3.2 RDFDB
The RDFDB stores all knowledge artifacts - such as ontologies, knowledge bases, and other data if available - in the RDF form. It is the MOLTO store and query service. The RDFDB has the following features:
- Default repository for structured data, which uses ORDI-SG integration layer over OWLIM – the fastest and most scalable Sesame Sail implementation;
- Storage and query APIs for the default repository, accessible over JMS;
- Storage and query APIs for the default repository, accessible through Sesame HTTP Server on port 9090.
| Attachment | Size |
|---|---|
| ordi.png | 28.05 KB |
3.2.1 Overview
Using the RDF model to represent all system knowledge allows an easy interoperability between the stored data and the conceptual models and instances. Therefore, if the latter are enriched, extended or partially replaced, it is not necessary to change the implementation considerably. However, the requirements for tracking of provenance, versioning and stored knowledge meta-data make the use of RDF triples insufficient. Therefore, we use RDF quintuples and a repository model that supports them.
We will expose an open API, based on the ORDI SG data model that can be implemented for integration with alternative back-ends. The ORDI SG model is presented here in further detail, as it is the basis for the RDFDB API.
The atomic entity of the ORDI SG tripleset model is a quintuple. It consists of the RDF data type primitives - URI, blank node and literal, as follows:
{P, O, C, {TS1, ..., TSn}, where:
- S is the subject of a statement; of the type URI or blank node;
- P is the predicate of a statement; of the type URI;
- O is the object of a statement; of the type URI, blank node or literal;
- C is the context of a statement (i.e. Named Graph); of the type URI or blank node;
- {TS1, ..., TSn} is an unordered set of identifiers of the triplesets to which the statement is associated; of the type URI or blank node.
The ORDI data model is realized as a directed labeled multi-graph. For backward compatibility with RDF, SPARQL and other RDF-based specifications, a new kind of information is introduced to the RDF graph. The tripleset model is a simple extension of the RDF graph enabling an easy way for adding meta-data to the statements.
It is a new element in the RDF statement, previously expressed as a triple or a quadruple, to describe the relation between the statement and an identifiable group of statements. This new term is introduced to distinguish the new model from several similar, already existing, RDF extensions and the terms associated with them:
- Context, as defined in several RDF APIs like Sesame 2.0, YARS and others;
- Datasets, as defined in SPARQL;
- Named-graphs, as introduced at http://www.w3.org/2004/03/trix/, implemented in Jena and used in SPARQL.
The following is true for the tripleset model:
- Each contextualized triple {S, P, O, C} could belong to multiple triplesets;
- The triples are not "owned" by the contexts; a triple can be disassociated from a tripleset without being deleted;
- When a triple is associated with several triplesets it should be counted as a single statement, e.g. a single arc in the graph;
- A tripleset can contain triples from different contexts;
- Each tripleset can be converted to a multi-set of triples, as one triple can correspond to multiple contextualized triples, belonging to the tripleset.
Figure 4 below is a diagram of the relationship between the major elements in the ORDI data model.
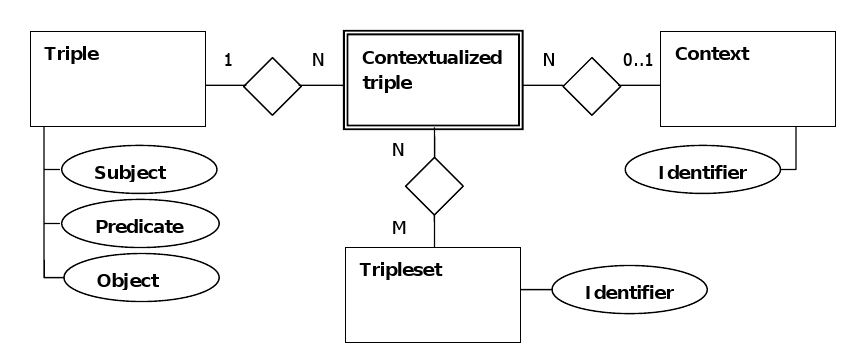
Figure 4 - Entity-Relationship Diagram of the ORDI Data Model
3.2.2 RDFDB Use
The RDFDB service is already available in the distribution and one could use it either by generating a JMS client or through the OpenRDF Sesame API.
Using the RDFDB by Generating a JMS Client
Generating a Client
Using your shell, navigate to the bin directory of the deployed platform and invoke the following commands:
mkproxy -proxy com.ontotext.platform.qsg.ServiceClass $PATH_TO_EXAMPLES/target/classes/
mkproxy -client com.ontotext.platform.qsg.ServiceClass $PATH_TO_EXAMPLES/target/classes/
Both commands dump output to sysout. Get the code, clean it as appropriate and put it in your project's source code. Build the project and the client is located in your project's target directory. The client implements the interface of the service.
Generating RDF-DB Clients
In order to use RDF-DB clients, the following services must be generated:
com.ontotext.rdfdb.ordi.OrdiService
com.ontotext.rdfdb.ordi.RdfStoreService
com.ontotext.rdfdb.ordi.RdfQueryService
Using the RDFDB through the OpenRDF Sesame API
By using the OpenRDF Sesame API one could manage and query the default repository through the Sesame Workbench, or operate over it using the HTTP Repository. The OpenRDF Sesame is integrated in the RDFDB. For more details about how to use it, please see the OpenRDF Sesame User Guide.