3. Project management during M19-M24
The third semester of the project saw the enlargement of the Consortium by two new partners University of Zürich and Be Informed. While the original planned start of the MOLTO-EEU project enlargement was scheduled for September 2011, and accounted for synchronicity of the deliverables with ongoing workpackages, the actual kickoff only happened in January 2012. Consequently, the end date of the project is now shifted to 31 May 2013 and the main deliverable of Workpackage 2 has been shifted 3 months to take into account the feedback from the new use cases added by the enlargement.
The following inconsistencies have been noticed in the revised Annex:
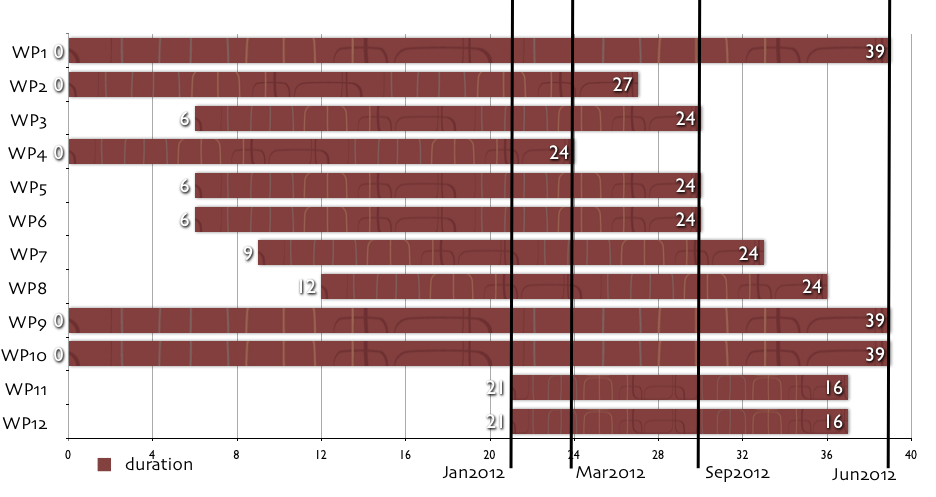
- WP12, on pag. 33, starts M22 ends 33, while on pag. 48, starts M18 ends M33. Figures on pag. 48 hold.
However, due to the delay in start, both WP11 and WP12 will now be ongoing in the period M22-M37, as in the chart below. Notice also the changes affecting WP2 and WP8.
Response to the review in March 2011
The following actions were taken as a result of the review report quoted here below.
Some observations, comments and remarks, raised and discussed at the review meeting, follow. These should be addressed in the respective deliverable(s) as well as in the planning for the next period.
Rule extraction (from lexical databases, ontologies, text examples) needs to be specified in detail and a concrete schedule should be included in the updated workplan (D1.1).
The workplan in maintained online using a dynamically generated list of tasks entered by the workpackage leaders. It is available, if logged in, under http://www.molto-project.eu/workplan and tasks http://www.molto-project.eu/workplan/tasks. It is the responsibility of the workpackage leader to actively use and document ongoing work using this tool.
The topic of rule extraction will be detailed in the last, main deliverable of WP2.
Concerning the integration of the TermFactory (TF) and Knowledge Representation Infrastructure (KRI), it seems that there are overlaps between these tools. The partners must clarify which functions of these tools will be used in the case studies in order to exploit complementarities of the tools and avoid overlaps.
The Term Factory is not only a component in molto but a stand-alone software, which vitally requires some functionalities of its own for technical purposes. Any excessive development of overlapping functions will avoided by co-operation and planning with the KRI developers. It is in deed notably relevant for evaluation and reporting that the case studies describe the tools that provide each functionality.
Critical issues with respect to the semi-automatic creation of abstract grammars from ontologies, as well as deriving ontologies from grammars, are still to be clarified. Concrete steps to handle these issues need to be specified in detail and a schedule should be included in the updated workplan (D1.1).
As part of the prototype for D4.3 an automatically build from an ontology abstract and concrete English grammar have been integrated. They are used to verbalize the results from the semantic repository. Experiments and discussions, about using a similar approach for automatically buiding a query grammar from the semantic repository, were performed, but the provided from UGOT GF query grammar was selected as better tool because of its expressing power and the possibilities to generate better natural language. The query grammar has different types of question templates and it can be easily ported for new domain with minor modifications at the abstract and concrete grammars. The mapping rules that are used for connection between the abstract grammar and SPARQL are selected as the best semi-automated aproach for connection between the grammar and SPARQL. The mapping rules provide possibilities to make an general rules for transformation, but also to make a fine tune for a specific cases. The rules that are currently used are general enough to be used at new domains with a ported GF query grammar and this will be demonstrated at WP7 and WP8 prototypes.
Current description of work in WP6 lacks details on the prototype multilingual dialog system to be developed. Including an example dialog and specifications of this prototype in a new version of deliverable D9.1 is recommended.
WP7 work should focus on the major issues examined in MOLTO, especially in relation to the grammar – ontology interoperability rather than chemical compound splitting. Specific scenarios are needed for the exploitation of MOLTO tools in this case study. It is recommended to include such scenarios in a new version of deliverable D9.1.
Specific scenarios are needed for the exploitation of MOLTO tools in the case study on cultural heritage (WP8) which just started. It is recommended to include such scenarios in a new version of deliverable D9.1.
Use cases are listed in http://www.molto-project.eu/workplan/usecases and they include two scenarios for WP8 and two for WP7. The specific use case scenarios for WP7 were described in: UC-71 and UC-72. Details about them were given in Section 2 of D.7.1.
UC-71 focuses on grammar-ontology interoperability. User queries, written in CNL (controlled natural language) are used to query the information retrieval system.
UC-72 focuses on high-quality machine translation of patent documents. It uses an SMT baseline system to translate a big dataset and fill up the retrieval databases. In order to study the impact of hybrid systems in translation quality, a smaller dataset will be translated using the hybrid system developed in WP5.
The way the project’s web site is structured, although it contains the necessary content, affects its readability in some cases.
We have added a direct navigation link to Sites and People, and a quick link to the public deliverables list. Publications can be tagged by workpackage or event, thus making the selection of publications by tag easier.
The deliverables on the workplan (D1.1) and the dissemination plan (D10.1) should be regularly updated (at the beginning of 2nd and 3rd year).
We have kept an updated list of deliverables with administrator's view at http://www.molto-project.eu/workplan/deliverables and quick links at http://www.molto-project.eu/view/biblio/deliverables. The dissemination plan is kept uptodate on the wiki page, http://www.molto-project.eu/wiki/living-deliverables/d101-dissemination-.... We now added a Section to summarize Exploitation plans.
Taking into account the numerous endeavors undertaken in the translation domain, both research and commercial, the market segment addressed by MOLTO should be identified with maximum precision. The specific case studies should also be taken into account in this effort. It is suggested that careful planning is initiated as early as possible and not later than the next reporting period.
The addition of the new partner BI will open extra markets for the tools of MOLTO. We have also started to look into usage of constrained natural languages in software localization, in social networks and in specific mathematical domains.