5. Example-based grammar writing process
ramona.enache
Multilingual Online Translation
The figure presents the process of creating a Phrasebook using an example-based approach for a language X, in our case either Danish, Dutch, German, Norwegian, for which we had to employ informed development and testing by a native speaker, different from the grammarian.
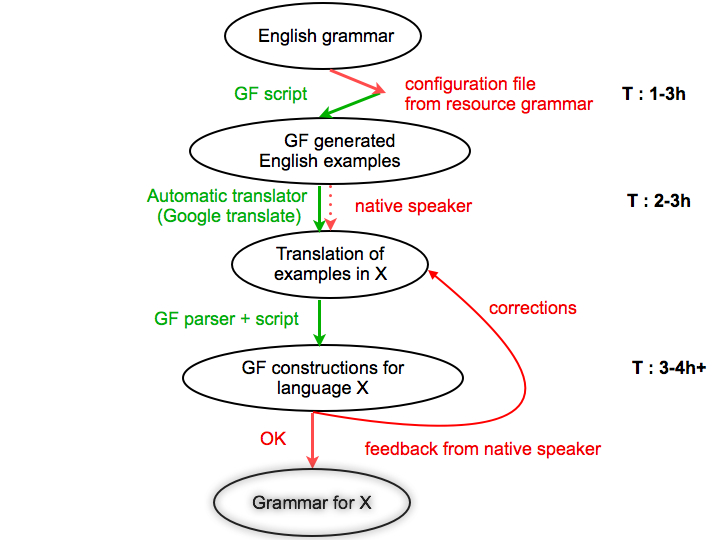
Remarks : The arrows represent the main steps of the process, whereas the circles represent the initial and final results after each step of the process. Red arrows represent manual work and green arrows represent automated actions. Dotted arrows represent optional steps. For every step, the estimated time is given. This is variable and greatly influenced by the features of the target language and the semantic complexity of the phrases and would only hold for the Phrasebook grammar.
Initial resources :
- English Phrasebook
- resource grammar for X
- script for generating the inflection forms of words and the corresponding linearizations of the lexical entries from the Phrasebook in the language X. For example, in the case of the nationalities, since we are interested in the names of countries, languages and citizenship of people and places, we would generate constructions like "I am English. I come from England. I speak English. I go to an English restaurant" and from the results of the translation we will infer the right form of each feature. In English, in most cases there is an ambiguity between the name of the language and the citizenship of people and places, but in other languages all three could have completely different forms. This is why it is important to make the context clear in the examples, so that the translation will be more likely to succeed. The correct design of the test of examples, is language dependent and assumes analysis of the resource grammar, also. For example, in some languages we need only the singular and the plural form of a noun in order to build its GF representation, whereas in other languages such as German, in the worst case we would need 6 forms which need to be rendered properly from the examples.
- script for generating random test cases that cover all the constructions from the grammar. It is based on the current state of the abstract syntax and it generates for each abstract function some random parameters and shows the linearization of the construction in both English and language X, along with the abstract syntax tree that was generated.
- Step 1 : Analysis of the target grammar
-
The first step assumes an analysis of the resource grammar and extracts the information needed by the functions that build new lexical entries. A model is built so that the proper forms of the word can be rendered, and additional information, such as gender, can be inferred. The script applies these rules to each entry that we want to translate into the target language, and one obtains a set of constructions.
- Step 2 : Generation of examples in the target language
-
The generated constructions are given to an external translator tool (Google translate) or to a native speaker for translation. One needs the configuration file even if the translator is human, because formal knowledge of grammar is not assumed.
- Step 3 : Parsing and decoding the examples with GF
-
The translations into the target language are further more processed in order to build the linearizations of the categories first, decoding the information received. Furthermore, having the words in the lexicon, one can parse the translations of functions with the GF parser and generalize from that.
- Step 4 : Evaluation and correction of the resulting grammar
-
The resulting grammar is tested with the aid of the testing script that generates constructions covering all the functions and categories from the grammar, along with some other constructions that proved to be problematic in some language. A native speaker evaluates the results and if corrections are needed, the algorithm runs again with the new examples. Depending on the language skills of the grammar writer, the changes can be made directly into the GF files, and the correct examples given by the native informant are just kept for validating the results. The algorithm is repeated as long as corrections are needed.
The time needed for preparing the configuration files for a grammar will not be needed in the future, since the files are reusable for other applications. The time for the second step can be saved if automatic tools, like Google translate are used. This is only possible in languages with a simpler morphology and syntax, and with large corpora available. Good results were obtained for German and Dutch with Google translate, but for languages like Romanian or Polish, which are both complex and lack enough resources, the results are discouraging.
If the statistical oracle works well, the only step where the presence of a human translator is needed is the evaluation and feedback step. An average of 4 hours per round and 2 rounds were needed in average for the languages for which we performed the experiment. It is possible that more effort is needed for more complex languages.
Further work will be done in building a more comprehensive tool for testing and evaluating the grammars, and also the impact of external tools for machine translation from English to various target languages will be analysed, so that the process could be automated to a higher degree for the future work on grammars.