5. Future direction: example-based grammar writing
ramona.enache
Multilingual Online Translation
It is typically the case that the writer of a GF concrete grammar is at least fluent in the language and has GF skills which are directly proportional with the complexity of the abstract syntax to implement. However, in the case of a rather complex multilingual grammar comprising 5 to more languages, as for instance was the case with the MOLTO Phrasebook(reference...) which was first available in 14 languages and which has a reasonably rich semantic interlingua, the task of finding grammar developers is a difficult one. Even if there exist such developers, their task can still be made easier, by trying to automate where possible, and alleviate over certain technicalities of GF programming that would slow down the grammar development.
When writing a application grammar, one such problem would be to use the resource library in order to build generate text for a given language with the help of the primitives already defined in the correspondent resource grammar. For this, however, one needs to be familiar with the almost 300 existing functions, assuming that the domain writer is different than the resource grammar write, as it is often the case.
In order to make the users' task easier, an API is provided so that the domain grammar writer only needs to know the GF categories and how they can be built from each other. This layer makes the interaction with the resource library smoother for users, and also makes it easier to make new constructions from the library available.
For example, the sentence "I talked to my friends about the book that I read", is parsed to the following abstract syntax tree:
UseCl (TTAnt TPast ASimul) PPos (PredVP (UsePron i_Pron) (ComplSlash (Slash3V3 talk_V3 (DetCN (DetQuant DefArt NumSg) (RelCN (UseN book_N) (UseRCl (TTAnt TPast ASimul) PPos (RelSlash IdRP (SlashVP (UsePron i_Pron) (SlashV2a read_V2))))))) (DetCN (DetQuant (PossPron i_Pron) NumPl) (UseN friend_N))))
If we use the API constructors, the abstract syntax tree is simpler and more intuitive:
mkS pastTense (mkCl (mkNP i_Pron) (mkVP (mkVPSlash talk_V3 (mkNP the_Art (mkCN (mkCN book_N) (mkRCl pastTense (mkRCl which_RP (mkClSlash (mkNP i_Pron) (mkVPSlash read_V2))))))) (mkNP (mkQuant i_Pron) plNum friend_N)))
In this way, the domain grammar writer, can just use the functions from the API, and combine them with lexical terms from dictionaries and functions from outside the core resource library that implement non-standard grammatical phenomena, that do not occur in all languages.
One step further in the direction of automating the development of domain grammars is to have the possibility to enter function linearizations as a positive example of their usage. This is particularly helpful in larger grammars containing syntactically complicated examples that would challenge even the more experienced grammarians. If instead an example is provided, even though the grammar could return more than one parse tree, the user can select the good tree or take advantage of the probabilistic ranking and take the most likely one.
The example-based grammar writing system is still work in progress, but there is a basic prototype of it available already, and it will be further developed and improved. The basic steps of the system will be shortly described further on, along with the directions for future work.
The typical scenario is a grammarian working on a domain concrete grammar for a given language - which we call X for convenience.
In this case, he would need at least a resource grammar for X. Preferably there should also be a large lexical dictionary and/or a larger-coverage GF grammar with probabilities. Currently, larger lexical resources exist for English, Swedish, Bulgarian, Finnish and French. For Turkish there exists a large lexicon also, but the resource grammar is not complete.
We also assume that the user has an abstract syntax for the grammar already and that the _lincats_ (namely representations of the abstract categories in the concrete grammar) are basic syntactic categories from the resource grammar(NP, S, AP).
Consequently, the functions from the abstract syntax will be grouped in a topological order, where the ordering relation a < b <=> b takes a as argument in a non-recursive rule. There are no cycles in this chain of ordered elements, since a similar check is being performed at the compilation stage. The elements will be ordered in a list of lists - where every sub-list represents incomparable elements. The user will be provided first with the first sub-list and after completing it, with the next ones.
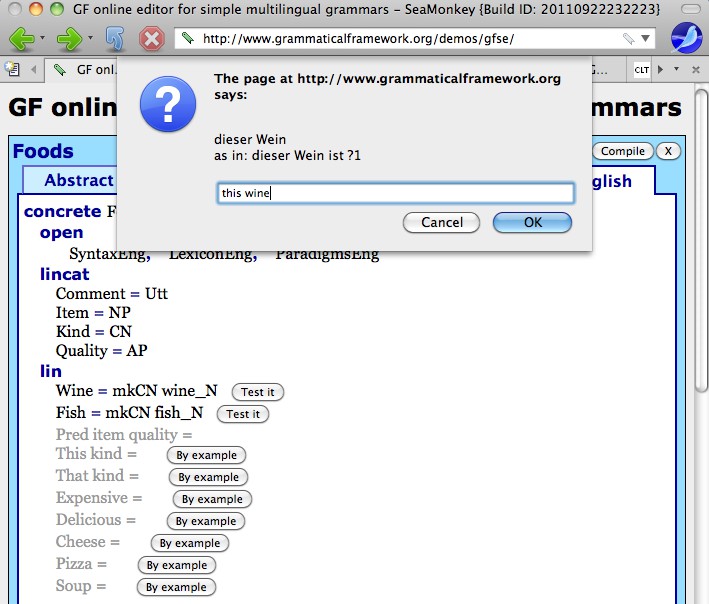
For each such function, an abstract tree from the domain grammar having as root the given function will be generated. The arguments are chosen among the functions already linearized. In case that another concrete grammar exists already, the user can also see a linearization of the tree in the other language, and also an example showing how the given construction fits into a context. For example, if the user needs to provide an example for Fish in a given grammar, say the tourist phrasebook, and there is an English grammar already then he would get a message asking him to translate fish as in "fish" / "This fish is delicious".
When providing the translation, the user will be made aware of the boundaries of the grammar, by the incremental parser of the resource grammar. If the example can be parsed and the number of parse trees is greater than 1, then either the user can pick the right one, or the system can choose the most probable tree as a linearization. From here, the system will also generalize the tree by abstracting over the arguments that the function could have. Finally the resulting partial abstract syntax tree will be translated to an API tree and written as linearization for the given function.
The key idea is based on parsing, followed by compilation to API and provides considerable benefits,especially for idiomatic grammars such as the Phrasebook, where the abstract syntax trees are considerably different. For example, when asking for a person's name in English the question "What is your name" would be written using API functions as:
mkQCl (mkQCl whatSg_IP (mkVP (mkNP (mkQuant youSg_Pron) name_N)))
which stands for the abstract syntax tree:
UseQCl (TTAnt TPres ASimul) PPos (QuestVP whatSg_IP (UseComp
(CompNP (DetCN (DetQuant (PossPron youSg_Pron) NumSg) (UseN name_N)))))
On the other hand, in French the question would be translated to "Comment t' appelles tu" (literally translated to "How do you call yourself") which is parsed to:
UseQCl (TTAnt TPres ASimul) PPos (QuestIAdv how_IAdv
(PredVP (UsePron youSg_Pron) (UseV appeler_V)))
and corresponds to the following API abstract tree:
mkQS (mkQCl how_IAdv (mkCl p.name appeler_V)))
Currently, steps are made to integrate the system with the Web Editor and in this way combine the example-based methods with traditional grammar writing. In this case the set of functions that can be linearized from example will be computed incrementally, depending on the state of the code.
A similar procedure to the one that determines which functions can be linearized from example can be used to find the functions that can be tested - functions already linearized that can be learned from example. In this way, the functions linearized in the editor - manually or by example can be also tested by randomly generating an expression and linearizing it in the language that is under development and also in one or more languages for which a concrete grammar exists. In case the linearization is not correct, the user can proceed to ask for a new example, or to modify the linearization himself.
Other plans for future work, in addition to integrate the method with the GF Web Editor, include a thorough evaluation of the utility of the method for larger grammars and with grammarians of different levels of GF skills. Moreover, we plan to include a handle for unknown words, that should make it easier for the user to build a small lexicon from examples.
As a solution to this, we devised the example-based grammar learning system, that is meant to automate a significant part of the grammar writing process and ease grammar development.
The two main usages of the system are to reduce the amount of GF programming necessary in developing a concrete grammar and the second and more important - to make possible learning certain features of a language for grammar development.
In the last years, the GF community constantly increased and so did the number of languages from the resource library and the number of domain grammars using them. The writer of a concrete domain grammar is typically different than the writer of the resource grammar for the same language, has less GF skills and is most likely unaware of the almost 300 constructors that the resource grammars implement for building various syntactical constructions; see http://www.grammaticalframework.org/lib/doc/synopsis.html.