3.1 The MOLTO Translation Tools (TT) Editor
olga.caprotti
Multilingual Online Translation
3.1.2.2 User version
All back-end requirements are needed also for the user version.
Now, instead of opening the package in Eclipse, the only thing needed is to place the following files under Apache2 server root (here /var/www) as shown.
/var/www/editor$ ls grammars index.html org.grammaticalframework.ui.gwt.EditorApp WEB-INF
Then, to run the editor, just type the address 127.0.0.1:8888/editor/index.html?gwt.codesvr=127.0.0.1:9997 into browser.
3.1.2.3 Limitations
Ideally, the same login should work throughout the different parts of the distributed toolkit. There should be some group scheme to set group level access restrictions. Eventually, we may want to provide MOLTO single-sign-on as a replacement for Google authentication.
3.1.3 Grammar manager
The prototype editor has a simple grammar manager that is supposed to allow a user to upload her grammars to the editor's grammar cache under her name. The cache kept is on the editor server for reasons of speed and xss restrictions. The user chooses the current grammar from among the cached grammars using a drop-down list.
3.1.3.1 Limitations
The grammar manager is not yet completed.
3.1.4 Document manager
The prototype editor has a simple document manager that saves a translated document in and retrieves one from from the mysql database using ContentService. The current document is saved in the database using a diskette icon on the editor page. The Documents tab shows the currently saved documents and allows the user to load a selected document for continued translation.
3.1.4.1 Limitations
Naming of documents is not yet supported. Both the grammar manager and document manager remain to be linked to the TMS.
3.1.5 Term manager
The TT editor includes a simple tabular equivalents editor for searching and editing translation correspondences from the web of data, including TermFactory services. The equivalents editor is an independent web application that may also be used standalone or as a plugin to other applications. When complete, the equivalents editor lets the user extend their GF grammars with terms entered in the term editor and/or upload them as term proposals to TermFactory.
3.1.5.1 Installation
The equivalents editor was built with the ExtJS javascript library. It can be downloaded from http://tfs.cc/molto/molto-term-editor.tgz. Unpack it and put the whole molto_term_editor directory under /var/www/ (or wherever your web server wants them, for example in Windows the path is probably C:\Program Files\Apache\htdocs). Open the file editor_sparql.html in a browser.
Note that this is also included in the complete editor as one of the tabs. As for function, the versions are identical. The screenshot below is from the standalone version.
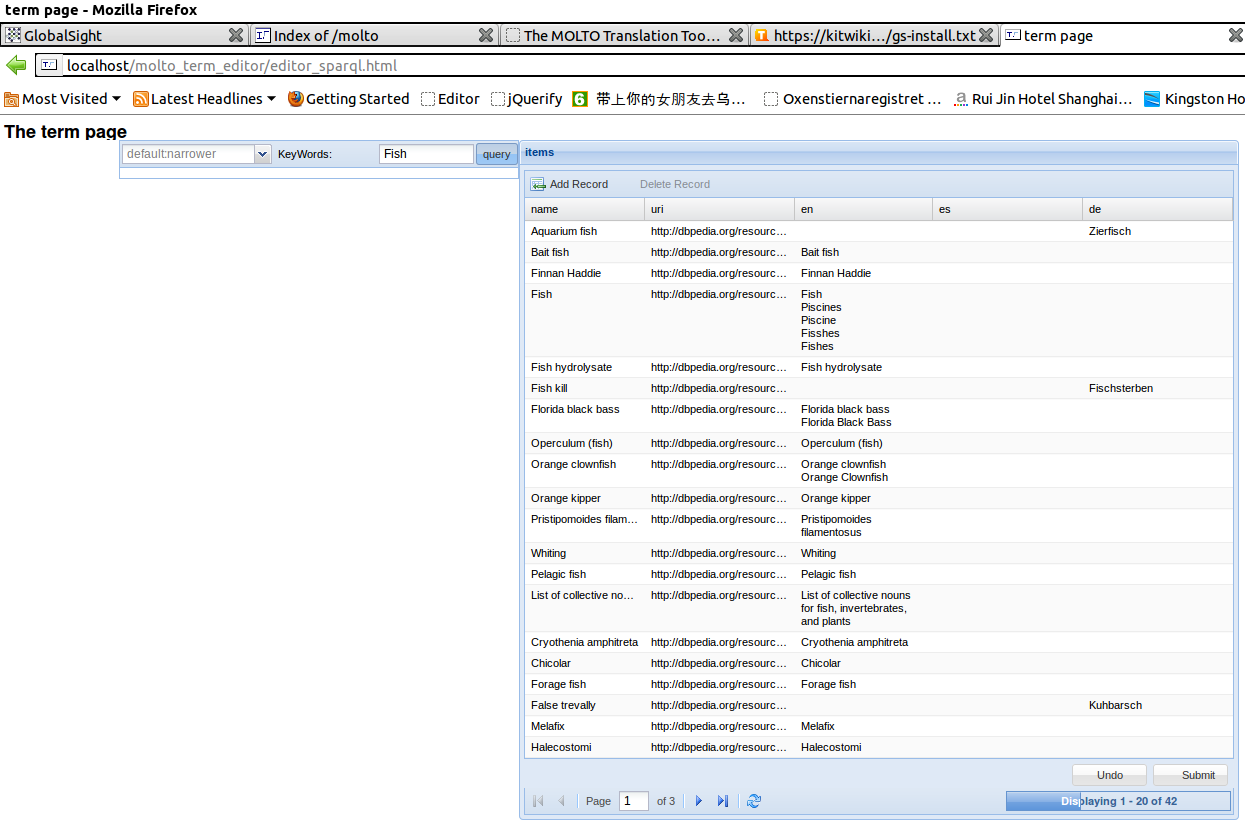
3.1.5.2 Use
The term editor consists of two tabular grids. In the first (left side) grid, enter a term in the text input and opt for wider or narrower concepts. In the latter case (the default) the editor shows on the right another grid of concepts that are classed narrower than the search term in the data source (by default, OntoText FactForge) and their designations in a predefined selection of languages. In the former case, the editor fills out the left side grid with concepts that are classed in the data source as wider than the search term. Clicking on one of them does a search for its subconcepts and terms, shown in the right side grid.
The term grid is editable and the editor remembers the user's edits to the cells in the grid.
3.1.5.3 Limitations
The data source and choice of languages are not yet user definable. The editor is not yet connected to the TermFactory or GF grammar back ends.
3.1.6 Editor
In the current version, there is a sign-in box and tabs for grammars, documents, editor, and terms, plus two to query and browse the loaded grammar. The latter services are familiar from other GF front ends and based on the GF grammar Web API.
3.1.6.1 Use
After sign in, the editor calls content-service to show the logged in user's grammars from the grammarusers mysql table in the grammar list. The user chooses a domain grammar. This brings to view the initial vocabulary known by the grammar as fridge magnets to choose from. Alternatively, the user can type or paste text in the editor window. At every new input, the active translation unit is sent to the back end for translation, and the set of fridge magnets is updated. When a translation unit is complete and translatable, it is simultaneously translated to all the available languages and the translations are shown on the screen (in blue). If an input is not parsable, the editor underlines the unparsable part. The user can back off to the point of deviation using backspace. In addition, There is a button for clearing the input.
The editor guides the text author by showing a set of fridge magnets and offers autocompletion to hint how a text can be continued within the limits of the current grammar.
3.1.6.2 Limitations
The prototype gives a first rough idea of how a web based GF translation editor could work. At present, however, it remains oriented to a very small vocabulary (fridge magnets are not apt to work well with thousands of words). It is also doubtful that the setup is fast enough for the amount of interactivity caused at speeds involved in professional translation. A reconsideration how the editor and the back end best play together is indicated. A related limitation is the strict left-to-right orientation of the parsing. UGOT seems to be working on a robust parser which allows other manners of combining parsing and editing. The proper disposition of the translation result is not worked out yet.