Patent Translation
Patent translation
Goals
Explore and build translation engines especialised for patent translation
Integrate the translations into the patents retrieval system
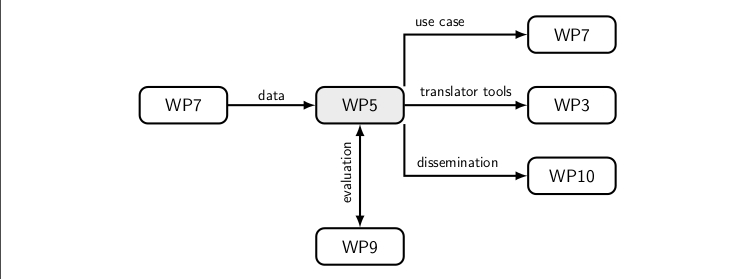
Division of work

Patents
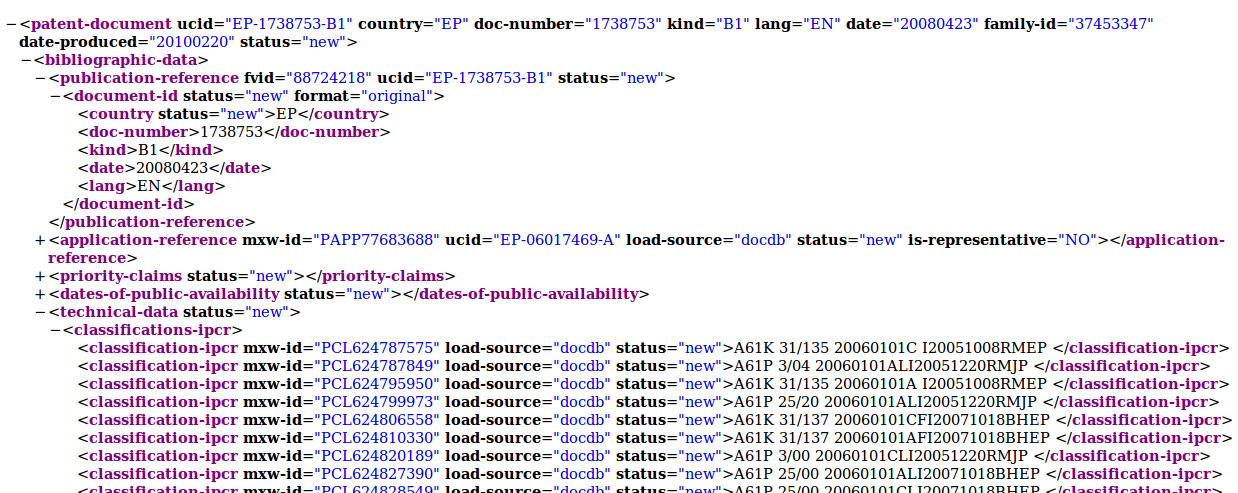
Patent documents
Meta-information
IPC classification A61P
Specific therapeutic activity of chemical compounds or medical preparations.

Patent documents
Text
Abstracts and claims

Patent documents
Language
Claims are written in a lawyerish style and using a very specific vocabulary of chemistry, full of compounds names.
The use according to claim 7, wherein said cancer diseases comprise bladder, lung, mamma, melanoma and prostate carcinomas.
A compound according to claim 1 wherein it is (2S)-2-[(4S)-4-(2,2-difluorovinyl)-2-oxopyrrolidinyl]butanamide.
The pharmaceutical composition according to claim 1 or 2, wherein said platinum anticancer agent is selected from at least one of the complexes having structures of: ** IMAGE **.
Corpus
Table here
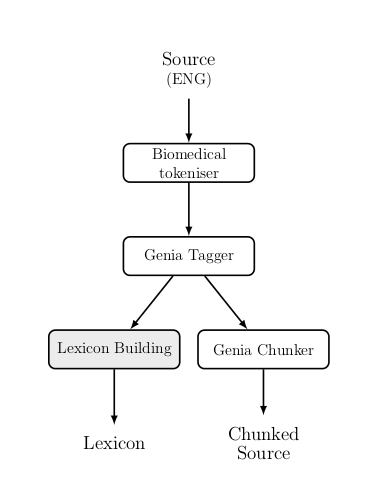
Pre-process
Different process for the translation engine and retrieval system
Common step: tokenising
Main difference: mark-up and semantic annotations
Tokenisation
Esquema + Exemple
8-difluoro-2- [ 3-fluoro-4 - [ ( L-lysyl ) amino ] phenyl ] -7-methyl-4H-1-benzopyran-4-one
vs.
8-difluoro-2-[3-fluoro-4-[(L-lysyl)amino]phenyl]-7-methyl-4H-1-benzopyran-4-one
Translation engines
Engines
Plot with SMT, GF => HYBRID
SMT for biomedical patents
Standard SMT system with
- Corpus: pre-processed corpus
- Language model: 5-gram interpolated Kneser-Ney discounting, SRILM Toolkit
- Alignments: GIZA++ Toolkit
- Translation model: Moses package
- Weights optimization: MERT against BLEU
- Decoder: Moses
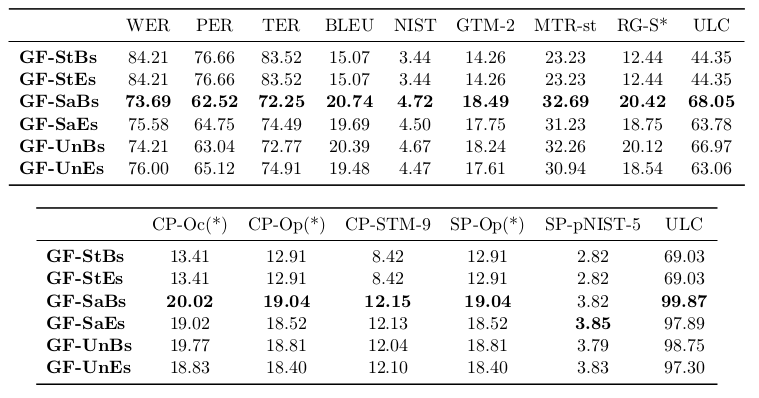
Evaluation in the biomedical domain
Syntactic metrics for MT evaluation
- MALT dependency parser for English and French
Berkeley parser for German
Similarity is computed as the overlap of the linguistic elements in the reference and the candidate.
- Liguistic elements can be either the lexical items, or the results of the parse, such as part-of-speech and phrase constituents.
SMT, automatic evaluation
En2Fr & En2De results
Also other language pairs?
GF for biomedical patents
Lexicon
Grammar
Translation by chunking
Methodology

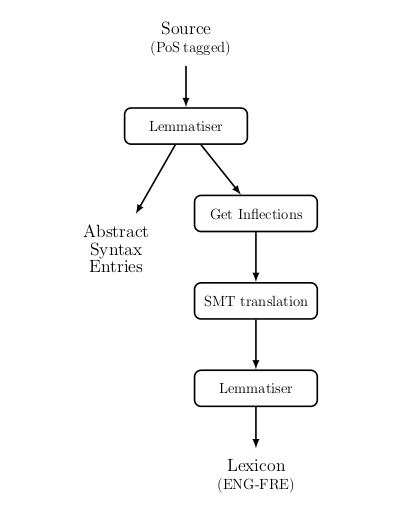
Lexicon building
Methodology

Lexicon building
German lexicon
*nucleotide sequence* -> Nucleotidsequenz
Word-to-word GIZA aligments not enough
Solution adopted:
Split compounds, word-to-word mapping, join afterwards
Lexicon building
Static vs. Runtime lexicons
RAMONA something here, please
Construction?
Lexicons for French and German
Sizes and sources for static, safe, unsafe, parse, noparse
RAMONA, please
French concrete grammar
Specific issues
NPs and AdvP are mapped into GF categories and linearised
VP, RelP and AdjP are linked to a NP in order to be linearised
Disambiguation of multiple linearisations by frequency counts in the corpus
French concrete grammar
Table with % of chunks translated
I need to choose only the representative systems (3?)
German concrete grammar
Specific issues
Nominalisation
*immunising* the mouse-> *das Immunisieren von* der Mouse
Gerund translated into infinitive + preposition (+ article)
Relative sentences
Pharmaceutical composition *comprising an aqueous solution*
Gerund and participle sentences not common in German
They are replaced by a relative clause during chunking
German concrete grammar
Table with % of chunks translated
As before I need to choose only the representative systems (3?)
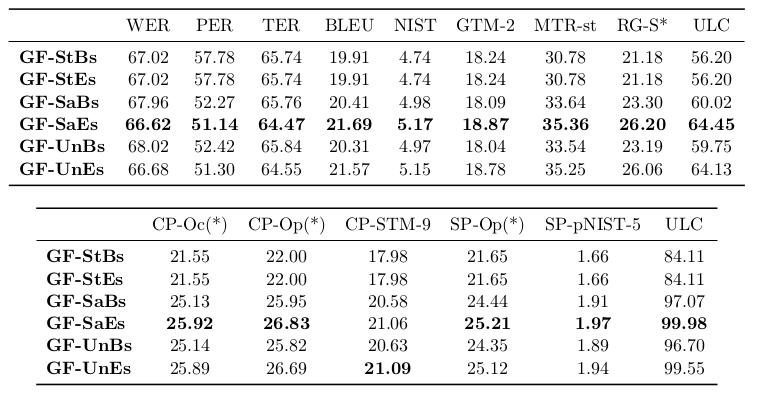
GF, automatic evaluation
Evaluation with lexical and syntactic metrics
1008 fragments from the MAREC test set
...
GF, automatic evaluation for En2Fr

GF, automatic evaluation for En2De

GF, robust parsing with patents
Robust parsing applied to patents
Pre-process and cleaning
From
The use of claim 23 , wherein the amount of said composition is from 100 mg to 800 mg of ibuprofen .
To
the use of claim 2 3 wherein the amount of said composition is from 1 0 0 mg to 8 0 0 mg of ibuprofen
Pre-process necessary for parsing
GF, robust parsing with patents
Parsing
- With C Runtime, parseEng, DictEng, ExtraLex
- Advantages: robustness
- Disadvantages: cleaning and length (<26 tokens)
Linearisation
- With parseGer, DictGer, ExtraLexGer
Use of generic resources (parseEng, DictEng, parseGer, DictGer) and domain lexicons (ExtraLex, ExtraLexGer)
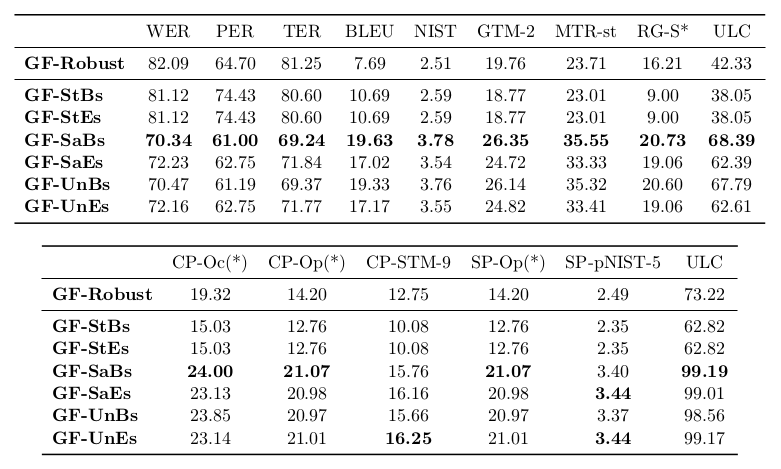
GF, robust parsing evaluation
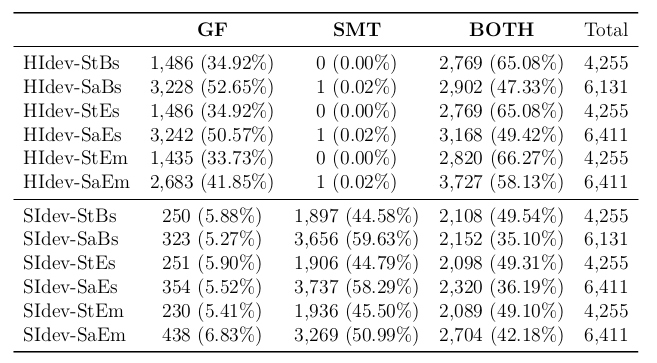
Experiment
Marec test set, 1008 fragments
Cleaning: 537 fragments
Properly linearised: 98 fragments
Evaluation with lexical and syntactic metrics
GF, robust parsing evaluation

Further hybridisation
SMT & GF integration lead by GF
GF grammar with SMT built lexicon and disambiguation by frequency counts
Robust parsing with statistical models for searching the space and for disambiguation
Further hybridisation
SMT & GF integration lead by SMT
Additional SMT decoding on top of GF and SMT to choose the best translation options
Hard Integration -- GF phrases are forced to appear -- SMT complements -- top SMT reorders
Soft Integration -- GF and SMT phrases interact -- top SMT reorders and chooses the best option -- LM plays an important role in choosing
Further hybridisation
SMT & GF integration lead by SMT
Integration only at decoding time Either Soft or Hard, it is applied on the test set
MERT with GF The final decoder weights are obtained also with an integration in development
Hybrid system
Final system
Characteristics and options
- static vs. dynamic lexicon (two types)
- base vs. extended lexicons
- single vs. multiple GF translations available
- hard vs. soft integration
- integration at decoding time vs. tuning
Hybrid system
Number of phrases from every system choosen at the end

Hybrid system
Automatic evaluation En2Fr
Table with the best systems
Hybrid system
Automatic evaluation En2De
Table with the best systems
Manual evaluation
Manual evaluation
Setup
Experiment definition
JUSSI, after the evaluation
Manual evaluation
Results
Table?
JUSSI, after the evaluation
Manual evaluation
Conclusions
JUSSI, after the evaluation
Patent translator usage
Patent translator usage
One-click system
Offline translation in the retrieval system
Translation tools?
Webservice?
One-click system
Perl script that runs the translator
csmisc14:hybrid cristina$ perl H1PTrad.pl
Usage: perl H1PTrad.pl -v # -m [runtime|unsafe|demo] [src2trg]
-v: verbosity [0,1,2]
-m: mode [runtime|unsafe|demo]
input: file to translate
src2trg: language pair
Ex: perl H1PTrad.pl -v 1 -m demo /Users/systems/input/patsA61P.test.en en2fr
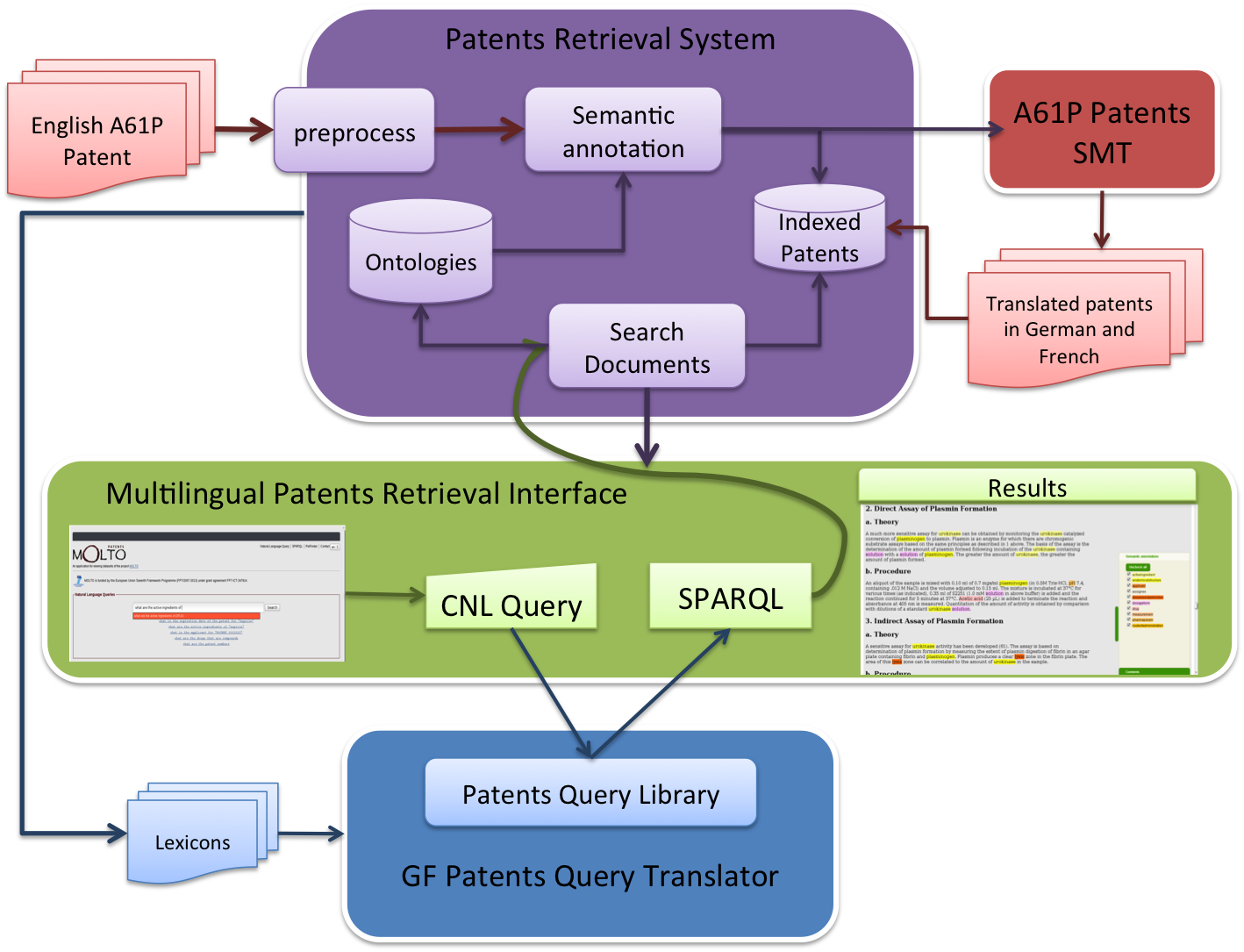
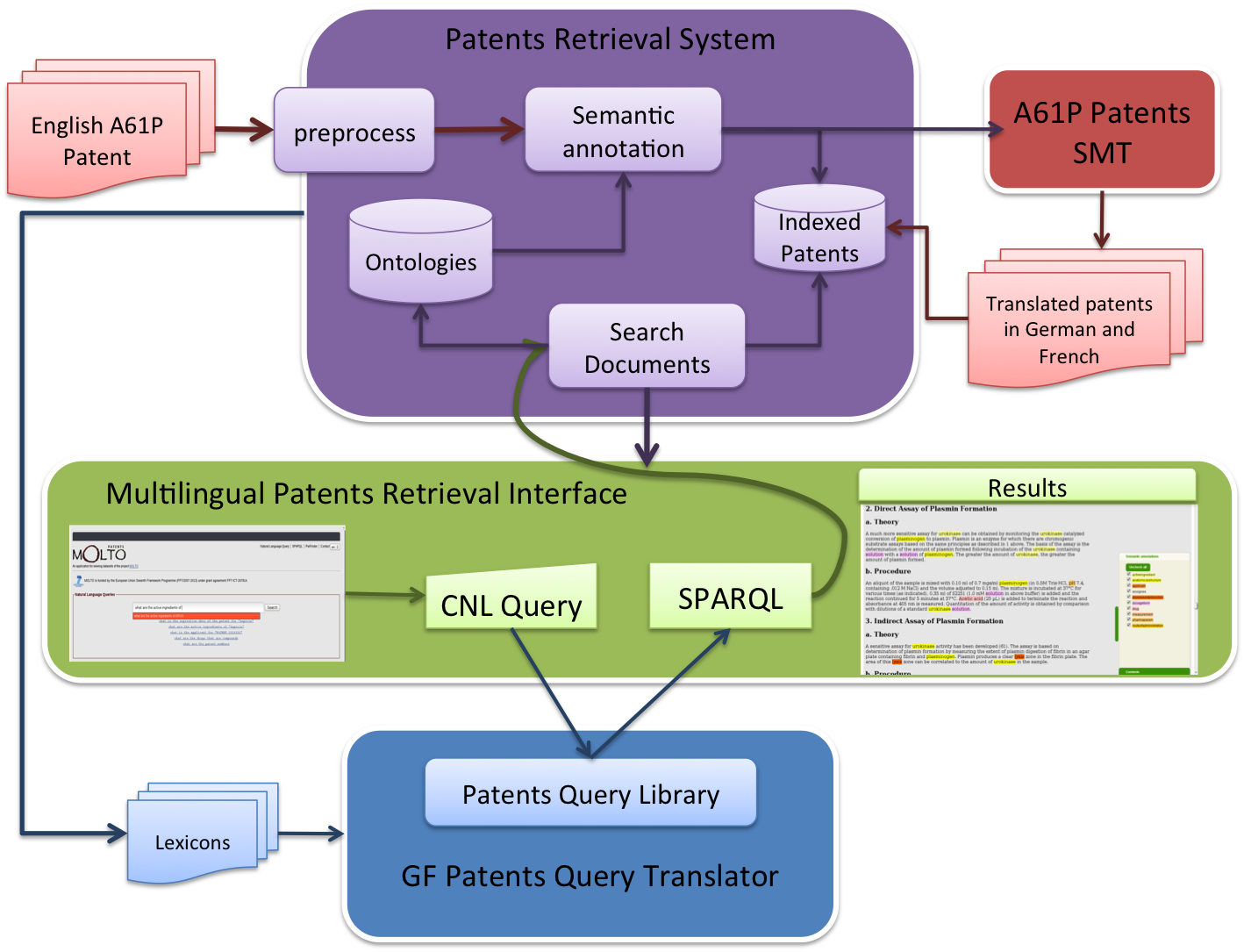
Patent translation & retrieval
Architecture

- SMT-based pipeline for automatic translation of annotated documents.
- multilingual document retrieval, discussed in the query flagship.
- GF-based querying subsystem for automatic translation of CNL queries to SPARQL. Further discussed in the query flagship.
- User Interface, shown as the case study in the query flagship.
Patent translation & retrieval
Dataset
- 7,705 documents, dated 2010 to 2012, downloaded from the EPO website
- 4,485 of them have claims, description and/or abstracts in English, the selected language to annotate the documents
| Documents | Claims | Descriptions | Abstracts | |
|---|---|---|---|---|
| English | 4,485 | 62,638 | 3,832 | 2,518 |
| German | 2,047 | 32,007 | 192 | 80 |
| French | 2,011 | 31,487 | 130 | 44 |
Patent translation & retrieval
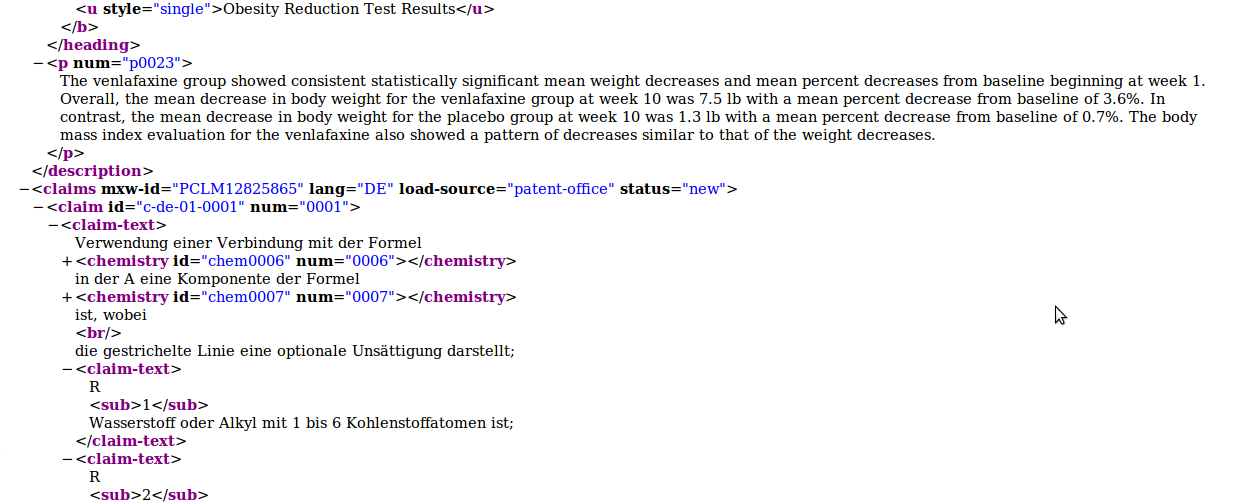
Semantic annotations and UTF-8 encode
```
The use of a compound of the formula:
or isomers i.e. geometric, optical, entianomeric, diasteriomeric, epimeric, stereoisomeric, tautomeric, conformational, or anomeric forms, salts, solvates and chemically protected forms thereof, in the preparation of a medicament for inhibiting the activity of PARP
, wherein: A and B together represent a fused aromatic ring, optionally substituted with one or more substituent groups selected from halo, nitro, hydroxy, ether, thiol, thioether, amino, C ${1-7}$ alkyl, C ${3-20}$ heterocyclyl and C $_{5-20}$ aryl;
R C is -CH $2$-R L , where R L is a C ${5-20}$ aryl group, optionally substituted with one or more substituent groups selected from C ${1-7}$ alkyl, C ${5-20}$ aryl, C $_{3-20}$ heterocyclyl, halo, hydroxy, ether, nitro, cyano, acyl, carboxy, ester, amido, amino, sulfonamido, acylamido, ureido, acyloxy, thiol, thioether, sulfoxide and sulfone; and
R N is hydrogen. ```
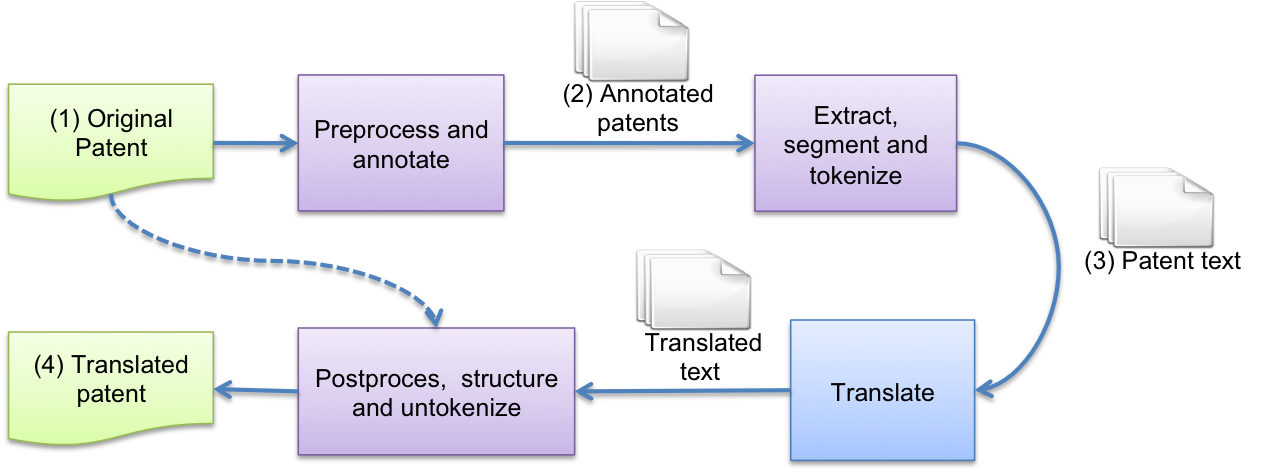
Patent translation & retrieval
Offline translation of the full dataset

- Cleaning and markup
- text extraction, tokenization and segmentation
- translation - Retraining of a new SMT using UTF-8 encoding
- postprocess, XML formatting and merge (EN,DE,FR)
Patent translation & retrieval
Online API
- http://falkor.lsi.upc.edu/MOLTO/
- Allows to upload a single file. It should contain text in English and annotations.
- It returns the same document with the english sections translated into German and French.
Patent translation & retrieval
The patents retrieval prototype
The interface is available in EN, DE and FR
Patent translation & retrieval
English text

French text

Webservice?
Something here?
Translator tools
screenshot if integrated
| Attachment | Size |
|---|---|
| AND_Q_DOC-en.png | 114.08 KB |
| AND_Q_DOC-fr.png | 102.52 KB |
| architectureWP7.png | 352.55 KB |
| architectureWP7.png | 352.55 KB |
| chunking.png | 20.01 KB |
| GFEn2De.png | 66.08 KB |
| GFEn2Fr.png | 68.34 KB |
| HphrasesEn2Fr.png | 79.29 KB |
| lexicon.png | 22.21 KB |
| patXML1.png | 173.17 KB |
| patXML2.png | 90.13 KB |
| process.png | 140.27 KB |
| relacions.jpg | 22.99 KB |
| RobustEn2De.png | 77.91 KB |
What links here
No backlinks found.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}