3. Workflows
This part consists of two separate workflow descriptions. The first workflow is that of a traditional professional translation, using the translation platform Pootle, with GF integrated in machine translation and translation memory. The second workflow describes a case where the translator is authorised to do changes to source. The tools of choice are the Simple Translation Tool and the Syntax Editor.
3.1. Translation of a fixed source
The workflow of a professional translation is often fairly complex, including roles such as project manager, translator and reviewers of both content and language. Machine translation is used as the translator's aid, along with other tools such as dictionaries and translation memories. This is an established practice in computer-assisted translation; one of the main objectives of WP3 is to demonstrate that MOLTO tools can be adapted in a traditional translation workflow.
The translator is not allowed to modify the source text, which is a serious limitation for the MOLTO translation, precision at the cost of coverage. However, in this scenario we assume that the translator necessarily knows both source and target languages. The role of the machine translation is not to provide publication quality text for blind translation, but to help the translator to produce translations.
When does it make sense to use MOLTO tools? With free text of unrestricted domains, the most common case is that GF grammars do not produce any translation at all, due to missing words or constructions. When we have a professional translator post-editing GF grammars beat general-purpose MT in situations where the structure is crucial. Any formulaic parts within unrestricted text, such as mathematical constructions (case study X) and chemical formulas (case study Y). A construction such as (2S)-2-[(4S)-4-(2,2-difluorovinyl)-2-oxopyrrolidinyl]butanamide is constructed by elaborate rules, which can be expressed precisely with a GF grammar. However, statistical machine translation fails to capture the structure, and the result is worthless for post-editing; a change, addition or omission of even one element is enough to change the formula completely.
Thus, we have integrated GF as one of the translation options in Pootle. The technical side is handled by GF Web API calls, explained in more detail in section 2.3.
3.1.1 The Pootle workflow
The Pootle translation enviroment implements the now industry-standard workflow where the translatable material, the translation memories and the editing tools reside on the same Web server. The system also includes rel-time word-count reporting, user management and terminology asset handling. This greatly reduces the effort needed for a translation project, as all the tools and resources are centralized. As the translations are updated into a shared translation memory in real time, the need to create, update and document the memories after the project is unnecessary. Pootle also allows the local downloading of necessary resources in cases where the translator does not have an always-on internet connection.
3.1.2 Translation project manager
The translation project manager can upload the files to be translated to the Pootle server and define the language pairs, translation memories, glossaries (either general or project specific) and file formats to be used in the translation. The systems allows the use of standard translation file formats like XLIFF (for source material), TMX (translation memories) and TBX (terminology). In our GF machine translation enabled version of Pootle, the PM can also select the GF grammar or grammars used for translation (see Section 2.3 for an example).
When the translation assets have been configured, the PM can give the necessary access rights to them for the translator s and reviewers. The material can also be translated as crowd-sourcing, so anyone with an access to the Pootle server can participate in the translation. This method has been used in many open-source localization projects, for example in the OpenOffice suite.
3.1.3 Translators
The translators can then log in with their credentials onto the Pootle server, and see all the translation tasks assigned to them by the PM:

After clicking a project name, the Languages page shows the target languages the translator has been assigned to:
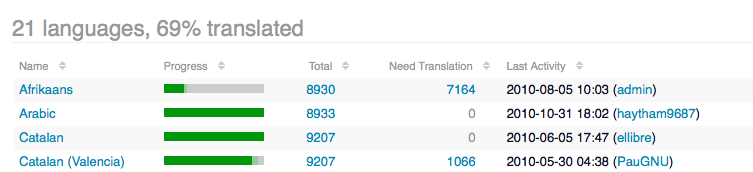
Clicking the language name opens the editing environment:
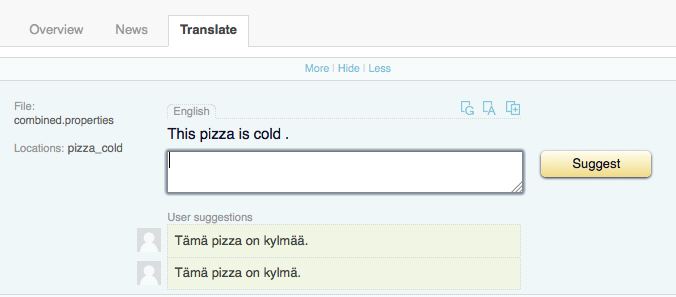
Any exact or fuzzy match ("Translation suggestion" in Pootle terminology) found in the translation memory can be selected and edited for a translation. As explained in the previous section, the translator can use machine translation services (including GF) by clicking the relevant button. The translator is thus able to use either the sugggestions from the translation memory, a choice of machine translations or a translate the segment from scratch.
The Pootle editing tool includes automatic checking for quality issues, for example missing tags, variables or numbers, wrong capitalisation, punctuation and so on, so the translator gets instant feedback on possible formatting errors in the translation. The translator is also able to include comments to reviewers and PMs as separate field in the tool and add or review terms in the terminology.
3.1.4 Review and post-processing
During the translation, the PM can follow the progress of the project on the Projects page. When the translation of a component is ready, the PM gets a notification, and the translation can be sent to reviewers, who then check and correct the translations by accepting or rejecting the suggestions. After the review process, the PM is again nofified, and the translated and reviewed file can be downloaded for post-processing.
3.2. Translation of an editable source
We hold on to the assumptions stated in D3.1:
- Translator is the author or is authorized to adapt the text to better satisfy the constraints of the translation grammar,
- Translator is native or fluent in the source language, and familiar with the domain or at least its special language in order to know how the message can be paraphrased,
- Translator is not required to know (all of) the target languages.
In a case of at least partially blind translation, the quality of MT needs to be excellent. External revisers can be added to this scenario as well, but we assume the quality to be in general good, errors are due to bugs in grammars and grammar writers are correcting them. A concrete scenario could be a multilingual website, where the authorized users can create content in any of the languages, and it is updated simultaneously into all of them. Assuming there are users for every language, they can work themselves as reviewers, providing feedback in case there is an error in the grammar. Then a grammar writer fixes the grammar, and the all structures that had the same problem will be updated.
There might be a source document or it can be created from scratch. In any case, there is a need for guided authoring, to ensure that the produced text is recognized by the grammar. This is not currently implemented, but planned by UGOT and explained further in section 4.2.
The Simple Translation Tool (STT) offers the functionalities for pre- and post-editing of MT. When needed, machine translation can be completely overridden by manual translation. The functionalities of STT are demonstrated with a toy text about pizzas. More complex grammars produced within MOLTO include the patent grammars in WP7 and the mathematical grammar library in WP6, but they are not integrated to STT at the moment. We plan to produce a video demo with some real use cases.
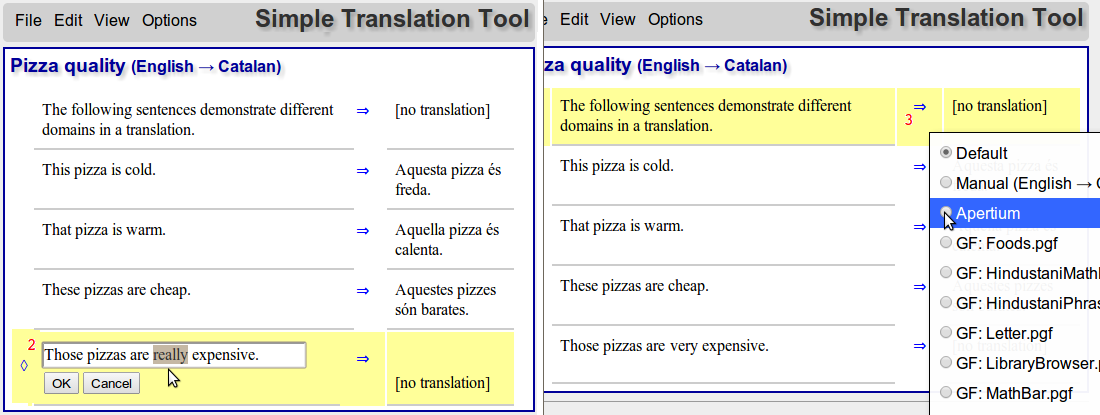
In the first image, the text is uploaded into STT and a default translation method is chosen.
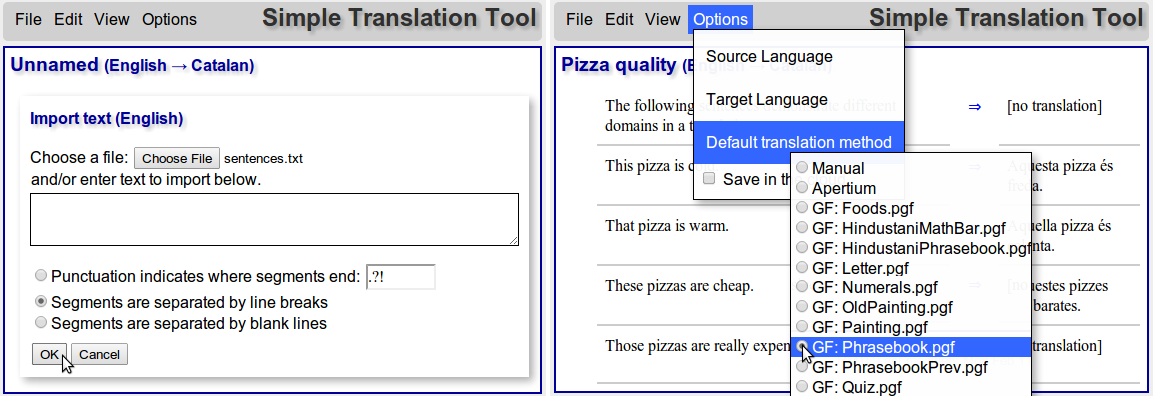
In the second image, we see three errors. The first one, indicated with number 1, is an error in the grammar; an unidiomatic word choice. This type of error is easiest to fix just by modifying the target -- followed by a bug report to a grammar writer. Of course, spotting this type of error requires that the translator knows the target language. In cases where not, they just need to assume that input is correct.
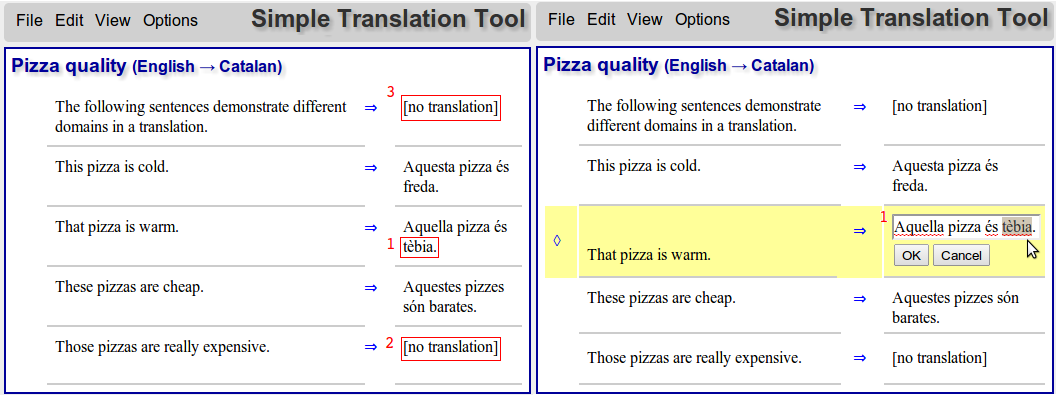
The second error manifests as no translation. The solution here is to paraphrase the source; in this case, changing the modifier "really" to "very", that is supported by the lexicon. This example is very simplified; in any realistic situation, the possible changes are numerous. Either we need to assume that the translator/author has a good documentation on the allowed constructions in the restricted language, or the program needs to guide the translator. The latter is a planned feature, the first depends on the individual use case.
The third error also shows no translation, but it is due to the segment being totally different domain. In the example document of 5 phrases, the first is a commentary, written on completely unrestricted text, and the four remaining phrases are the sort of restricted language that translates with our chosen GF grammar. In a realistic situation, the first phrase could be generic instructions and the latter ones could be mathematical formulas, in order for the scenario to make sense. In any case, the error is corrected by changing the translation method for that segment. Instead of any GF grammar, we choose Apertium, with more coverage but quality not quaranteed. In case the translator spots errors in generic MT option, there is the source post-editing option.
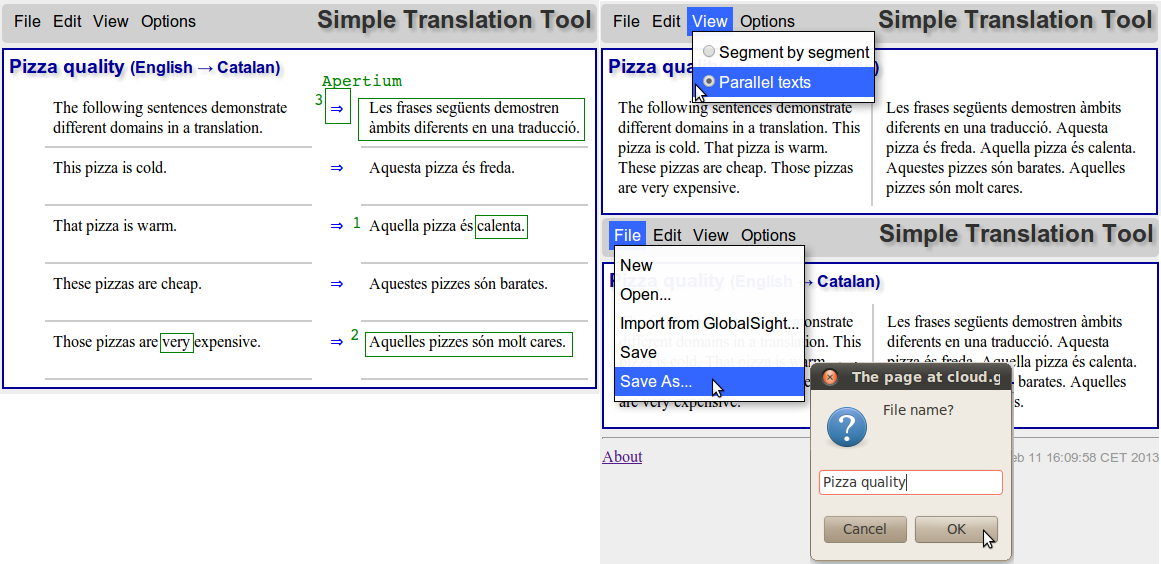
Finally, all three errors have been corrected. The user can view the texts parallel and save the project.
- Printer-friendly version
- Login to post comments
- Slides
What links here
No backlinks found.

