4. MOLTO Translation tools API
The MOLTO Translation Tools API exposes the most important operations used in translating with GF in MOLTO. It makes them available for programmers who want to create alternative accesses to GF translation tools, besides the MOLTO web translation demo platform. The API is divided into a Core API basically answering the needs of a single author/translator, and an Extended API addressing the needs of a community of authors, translators, and grammar engineers.
The components of the MOLTO TT Core API include at least the following:
- sign in
- grammar manager
- document manager
- term manager
- translation editor
The components of the MOLTO TT Extended API include the following:
- user management
- grammar management
- document management
- lexical resources
- translation editing
- translation memory
- reviewing/feedback
- grammar engineering
The first five are extensions of the corresponding facilities in the Core API. The lexical resources API borrows from TermFactory. The translation memory and the reviewing/commenting facilities are adapted from GlobalSight. The last item is based on the GF grammar development tools API.
The MOLTO Translation Tools Core API
The core API basically provides for the one-editor/translator scenario, where an editor/translator creates or edits a source document under constraints of a selected GF grammar in PGF form and generates translations for the source. For lexical gaps (out-of-vocabulary items) there is a simple term editor which allows looking up concepts and adding equivalents. The demo prototype translation editor
This section describes the translation editor developed by K. Angelov at UGOT.
To guide the development of a suitable translation editor API to support MOLTO translation needs, UGOT has created a prototype web-based translation editor. It is implemented in Google Web Toolkit. It is usable for authoring with small multilingual grammars. It doesn't require any downloads or use of command shells. All that is needed is a reasonably modern web browser.
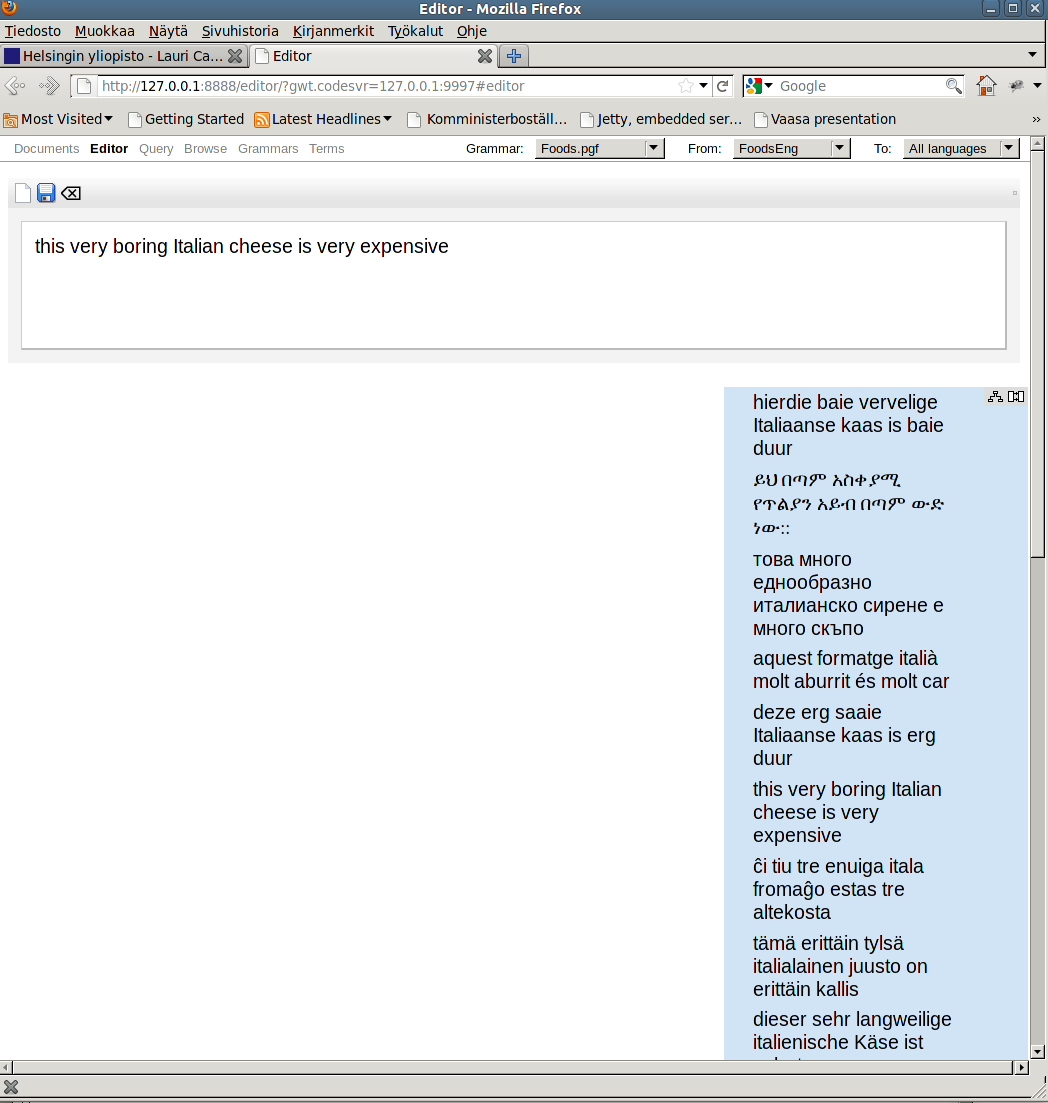
The editor runs entirely in the web browser, so once you have opened the web page and have documents and grammars loaded, you can continue translation editing while you are offline.
Sign in
Signing in should allow a user controlled access to her own and some (maybe not all) shared resources. Ideally, the same login should work throughout the different parts of the distributed toolkit. There should be some group scheme to set group level access restrictions.
- For basic sign in needs, the demo editor currently uses the Google authentication API.
Web applications that need to access services protected by a user's Google or Google Apps (hosted) account can do so using the Google Authentication service. This service lets web applications get access without ever handling their users' account login information. Google offers two libraries for handling authentication: one using the OAuth open standard, and a second interface called AuthSub, developed prior to the release of the OAuth standard. Authentication and authorization for Google APIs allow third-party applications to get limited access to a user's Google accounts for certain types of activities.
Grammar manager
The demo editor has a simple grammar manager that retrieves the user's grammars from a mySQL database via a ContentService implemented in Haskell, subject to a successful login through Google.
Available operations in ContentService:
- login
- update_grammar
- delete_grammar
- grammars (listing)
- save
- load (document from mysql db)
- search
- delete
Document manager
The demo editor has a simple file database manager that uploads and requests the user's documents from a mysql database using the same ContentService as the grammar manager.
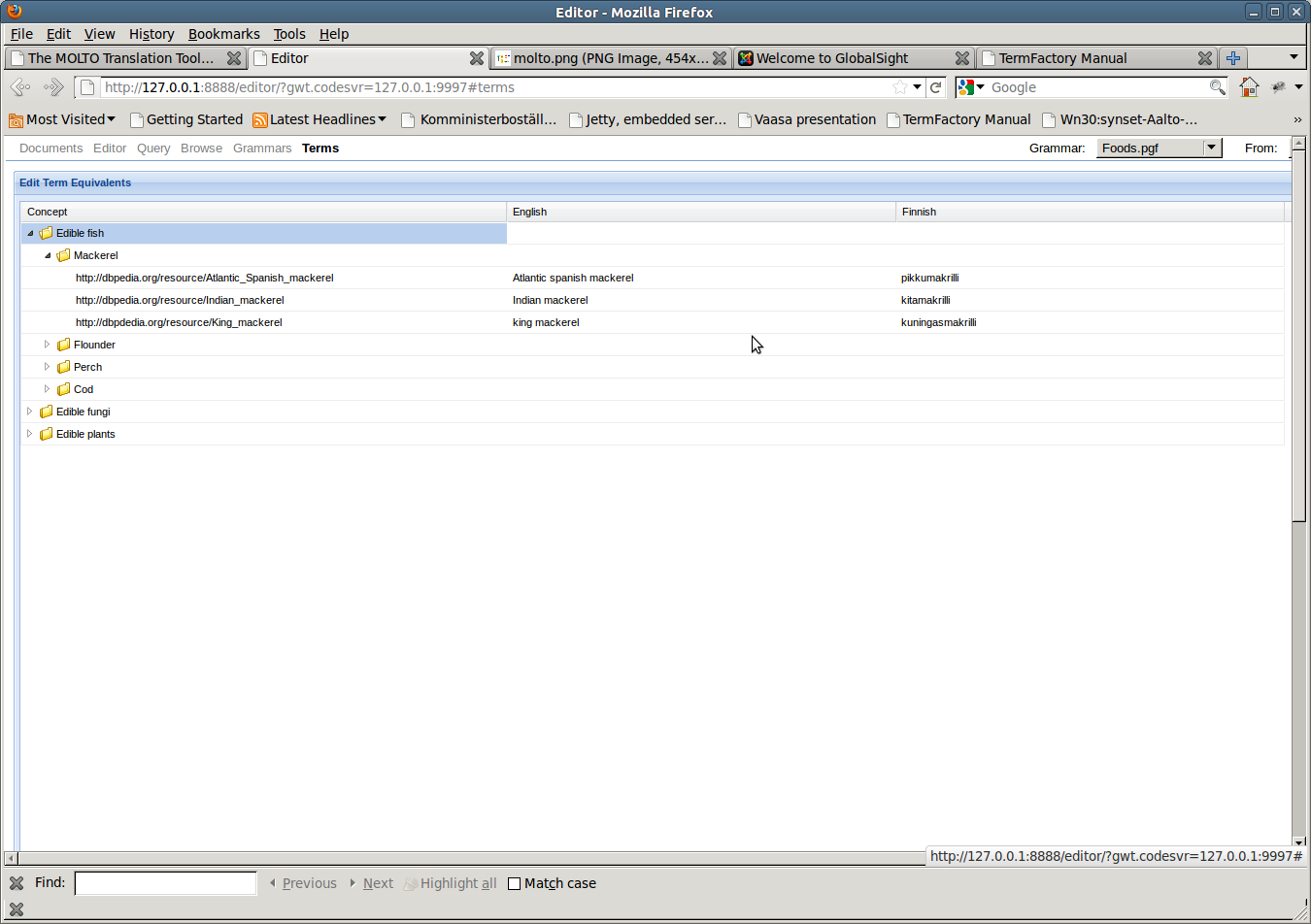
Term manager
The demo editor has a simple treegrid editor for searching and editing translation correspondences from the web of data, including TermFactory services. It is not yet connected to the GF grammar back end. The management of lexical resources and ontologies is detailed in connection with the extended API below.
Editor
The editor guides the text author by showing a set of fridge magnets and offers autocompletion to hint how a text can be continued within the limits of the current grammar. In the current version, there is a sign-in box and tabs for grammars, documents, editor, and terms, plus two to query and browse the loaded grammar.
The prototype gives a first rough idea of how a web based GF translation editor could work. While this editor is implemented in JavaScript and runs entirely in the web browser, we do not expect to create a full implementation of the MOLTO translation tools that runs in the web browser, but let the editor communicate with outside servers, including a TMS server (Globalsight) and a GF server.
The MOLTO Translation Tools Extended API
User management
For more flexibility (as well as vendor independence), an open source LDAP (The Lightweight Directory Access Protocol) based user management implementation can be used. There is one in GlobalSight. It allows distinguishing different roles and user groups, and controlling access to resources by roles.
Document management
The simple document manager of the demo editor will be complemented with a more sophisticated XLIFF based document manager built using the GlobalSight document management API. Document format conversions belong to the day's work in the translation business, and they can be assumed to be handled by the extended dcoument manager, using XLIFF as a fixpoint.
XLIFF (XML Localisation Interchange File Format) is an XML-based format created to standardize localization. XLIFF was standardized by OASIS in 2002. Its current specification is v1.2[1] released on Feb-1-2008. The XLIFF Technical Committee is currently at work on XLIFF 2.0. The specification is aimed at the localization industry. It specifies elements and attributes to aid in localization.
XLIFF cognizant open source editors and localization platforms include
- Benten - an open source XLIFF editor written in Java.
- OmegaT - a cross-platform and open source CAT tool.
- Pootle - a web-based localisation platform.
- Heartsome - a suite of cross-platform CAT (Computer-assisted translation) tools founded on open standards: XLIFF, TMX, TBX, SRX, XML, GMX. It also provides a free Lite version.
- Swordfish III - a cross-platform CAT tool that uses XLIFF 1.2 as native format.
- Virtaal - an open source CAT tool.
- XTM - a highly collaborative web server based CAT environment with extensive support for XLIFF (1.0 through to 1.2) as well as an implementation of the OASIS OAXAL architecture.
Examples of XLIFF Documents
Example 1: A simple XLIFF file with strings extracted from a Windows RC file. Here the skeleton (the data needed to reconstruct the original file are) is stored in a separate file:
<?xml version="1.0" encoding="windows-1252" ?>
<xliff version="1.1" xml:lang='en'>
<file source-language='en' target-language='fr' datatype="winres"
original="Sample1.rc">
<header>
<skl><external-file href="Sample1.rc.skl"/></skl>
</header>
<body>
<group restype="dialog" resname="IDD_DIALOG1">
<trans-unit id="1" restype="caption">
<source>Title</source>
</trans-unit>
<trans-unit id="2" restype="label" resname="IDC_STATIC">
<source>&Path:</source>
</trans-unit>
<trans-unit id="3" restype="check" resname="IDC_CHECK1">
<source>&Validate</source>
</trans-unit>
<trans-unit id="4" restype="button" resname="IDOK">
<source>OK</source>
</trans-unit>
<trans-unit id="5" restype="button" resname="IDCANCEL">
<source>Cancel</source>
</trans-unit>
</group>
</body>
</file>
</xliff>
Example 2: an XLIFF document storing text extracted from a Photoshop file (PSD file) and its translation in Japanese:
<xliff version="1.2">
<file original="Graphic Example.psd"
source-language="en-US" target-language="ja-JP"
tool="Rainbow" datatype="photoshop">
<header>
<skl>
<external-file uid="3BB236513BB24732" href="Graphic Example.psd.skl"/>
</skl>
<phase-group>
<phase phase-name="extract" process-name="extraction"
tool="Rainbow" date="20010926T152258Z"
company-name="NeverLand Inc." job-id="123"
contact-name="Peter Pan" contact-email="ppan@xyzcorp.com">
<note>Make sure to use the glossary I sent you yesterday.
Thanks.</note>
</phase>
</phase-group>
</header>
<body>
<trans-unit id="1" maxbytes="14">
<source xml:lang="en-US">Quetzal</source>
<target xml:lang="ja-JP">Quetzal</target>
</trans-unit>
<trans-unit id="3" maxbytes="114">
<source xml:lang="en-US">An application to manipulate and
process XLIFF documents</source>
<target xml:lang="ja-JP">XLIFF 文書を編集、または処理
するアプリケーションです。</target>
</trans-unit>
<trans-unit id="4" maxbytes="36">
<source xml:lang="en-US">XLIFF Data Manager</source>
<target xml:lang="ja-JP">XLIFF データ・マネージャ</target>
</trans-unit>
</body>
</file>
</xliff>
XLIFF is bilingual (each translation unit offers a and a elements). There are however ways to have multilingual XLIFF documents:
- Each <file> element can have different source/target pairs.
- The language of the data in the <alt-trans> element can be different from the main source/target languages. This allows alternative translations coming from a different language. For example: French (fr-FR) proposed translations could be offered when translating into French Canadian (fr-CA), and so forth.
In the GF interlingual model, the source "language" can be the abstract syntax representation of a translation unit.
The above considerations entail some requirements for translation-time document management in the MOLTO Translation tools API:
Associated to the MOLTO Translation Tools API, there must be tools for extracting XLIFF content documents out of various types of original skeleta and putting translated content back to the skeleton. (These tools are outside of MOLTO proper on the because many such tools already exist and because it is up to the provider of a new document type to also provide XLIFF support for it.)
There must be methods in the Molto Translation API for extracting raw text from XLIFF source elements, feeding it into GF and inserting the translation into the XLIFF target element. The GF translation API should also have methods for handling XLIFF coded inline tags. The best solution for that could be a special purpose GF grammar, because the correct placement of inline tags can depend on the translation of the content.
Lexical resources
A key consideration for the usability of MOLTO translation is the ease with which its text coverage can be extended by a user community. We need to pay great attention to adaptability. The most important factor in extensibility is lexical coverage. Grammatical coverage can be developed and maintained with language engineering, and grammatical gaps can often be circumvented by paraphrasing. There are two cases to consider: either the abstract grammar misses concepts, or concrete grammars for some language/s are missing equivalents. In the first case, we need to extend the domain ontology and its abstract grammar. In the second case, we need to add terms.
For ontology and term management, we propose to apport to MOLTO the TermFactory ontology based terminology management concept. TermFactory is a system of distributed multilingual term ontology repositories maintained by a network of collaborative management platforms. It has been described at length in the TermFactory Manual at http://www.helsinki.fi/~lcarlson/CF/TF/doc/TFManual_en.xhtml.
The user of the MOLTO translation editor has direct access to the treegrid editor for querying and editing term equivalents for concepts already in available ontologies, either already in TermFactory or 'raw' from the Web of Data, in particular, the OntoText services serving data from FactForge repository.
Term management
Say for instance there is no equivalent listed for cheese in some language's concrete grammar FooLang. The author/translator can use the treegrid editor to query for terms for the concept food:Cheese in TermFactory or do a search through OntoText services for candidate equivalents, or, if she knows the answer herself, submit equivalents through the treegrid editor. The new equivalent/s are saved in the user's own MOLTO lexicon, and submitted to TermFactory as term proposals for the community to evaluate.
Ontologies
If there is a conceptual gap not easily filled in through the treegrid editor, there is the option of forwarding the problem to an appropriate TermFactory collaborative platform. This route is slower, but the quality has a better guarantee in the longer run, as inconsistency or duplication of work may be avoided. Say there is no concept in the domain ontology for the new notion that occurs in the source text. In easy cases, new concepts can be added through the treegrid editor, subclassing some existing concept in the ontology. In more complex cases, where negotiations are needed in the community, an ontology extension proposal is submitted through a TermFactory wiki. TermFactory offers facilities for discussing and editing ontologies and their terms. In due time, them modified ontology gets implemented in a new release of the GF domain abstract grammar. Translation editing
The translation editor demo is a good prototype, but different scenarios and platforms may call for different combinations of its features. One way to go is to extend the demo with further tabs and facilities for CAT tool support. But there is the also the opposite alternative to consider of calling MOLTO translation tool services from a third party editor. GlobalSight has two built in translation editors, called popup editor and inline editor. The popup editor is a Trados TagEditor lookalike, while the inline editor has something of the look and feel of old Trados versions running WYSIWYG on Microsoft Word. The inline editor has been implemented in javascript using the FCKEditor library. It might just be feasible to embed MOLTO demo editor functionalities into the GlobalSight editor(s). In the Globalsight setup, there is already support for importing cut-and-dried MT translations from a MT service, but here we are talking about something rather more intricate.
It is not immediately obvious which route would provide least resistance. From the point of view of GF usability, finding a neat way of embedding GF editing functions in third party translation editors could be a better sales position than trying to maintain a whole new MOLTO translation environment. (Unless of course, the new environment is clearly more attractive to targeted users than existing ones.) We may also try to have it both ways.
Reviewing/feedback
It was noted above that blind translation in the case of incomplete or inadequate coverage in resource grammars can occasion a round of reviewing and giving feedback on the translations before publication. This part of the process is in its main outlines familiar from the translation industry workflow, and can be implemented as a variation of it. In the MOLTO workflow, reviewer comments are not returned (just) to the human author/translator(s), but they should have repercussions in the ontology and grammar management workflows. This part requires modifying and extending the existing GlobalSight revisioning tools to communicate with the MOLTO lexical resources and grammar services. The GlobalSight revisioning tools now use email as the human-to-human communication channel. We probably want to use a webservice channel for machine-to-machine communication, and possibly some web commenting system as an alternative to email.
Grammar engineering
To the extent grammar engineering can be delegated to translation tool users, it must happen transparently without requiring knowledge of GF. One way to do this is through what is known as example-based grammar writing in GF. Example-based grammar writing is a new GF technique for backward-engineering GF source from example translations. It can play a significant role in the translation-to-grammar feedback cycle. This part of the TT API will be borrowed from the MOLTO Grammar Developer Tools API. See the last section of this document.
- Printer-friendly version
- Login to post comments
- Slides
What links here
No backlinks found.

