1. Publishable Summary
This section must be of suitable quality to enable direct publication by the Commission and should preferably not exceed four pages.
In line with this, diagrams or photographs illustrating and promoting the work of the project, as well as relevant contact details or list of partners can be provided without restriction.
Project context and objectives
The project MOLTO - Multilingual Online Translation, started on March 1, 2010 and will run for 36 months. It promises to develop a set of tools for translating texts between multiple languages in real time with high quality. MOLTO will use multilingual grammars based on semantic interlinguas and statistical machine translation to simplify the production of multilingual documents without sacrificing the quality. The interlinguas are based on domain semantics and are equipped with reversible generation functions: namely translation is obtained as a composition of parsing the source language and generating the target language. An implementation of this technology is provided by GF, Grammatical Framework. GF technologies in MOLTO are complemented by the use of ontologies, such as used in the semantic web, and by methods of statistical machine translation (SMT) for improving robustness and extracting grammars from data.
MOLTO is committed to dealing with 15 languages, which includes 12 official languages of the European Union - Bulgarian, Danish, Dutch, English, Finnish, French, German, Italian, Polish, Romanian, Spanish, and Swedish - and 3 other languages - Catalan, Norwegian, and Russian. In addition, there is on-going work on at least Arabic, Farsi, Hebrew, Hindi/Urdu, Icelandic, Japanese, Latvian, Maltese, Portuguese, Swahili, Tswana, and Turkish.
Tools like Systran (Babelfish) and Google Translate are designed for consumers of information, but MOLTO will mainly target the producers of information. Hence, the quality of the MOLTO translations must be good enough for, say, an e-commerce site to use in translating their web pages automatically without the fear that the message will change. Third-party translation tools, possibly integrated in the browsers, let potential customers discover, in their preferred language, whether, for instance, an e-commerce page written in French offers something of interest. Customers understand that these translations are approximate and will filter out imprecisions. If, for instance, the system has translated a price of 100 Euros to 100 Swedish Crowns (which equals 10 Euros), they will not insist to buy the product for that price. But if a company had placed such a translation on its website, then it might be committed to it.
There is a well known trade-off in machine translation: one cannot at the same time reach full coverage and full precision. In this trade-off, Systran and Google have opted for coverage whereas MOLTO opts for precision in domains with a well understood language. Three such domains will be considered during the MOLTO project: mathematical exercises, biomedical patents, and museum object descriptions. The MOLTO tools however will be applicable to other domains as well. Examples of such domains could be e-commerce sites, Wikipedia articles, contracts, business letters, user manuals, and software localization.
Main results achieved so far
A few results have been already achieved during the first semester of the project's lifetime. Two applications of the MOLTO translation web services are online on the project web pages: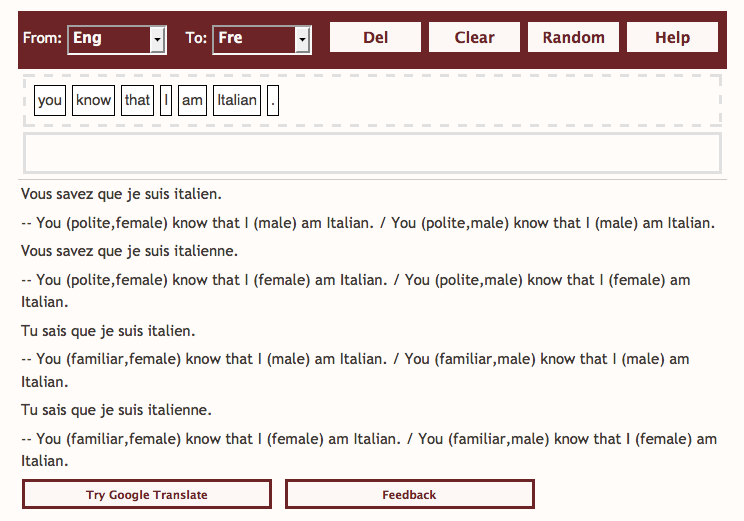
- The travel phrasebook translates sentences to 14 different languages and shows some of the major end-user features available to MOLTO users: predictive typing and JavaScript-based GUI. Predictive typing prompts the user with the next available choices mandated by the underlying grammar and offers quasi-incremental translations of intermediate results from words or complete sentences. JavaScript-based GUI using off-the-shelf functions can be readily deployed on any device where a browser is available.
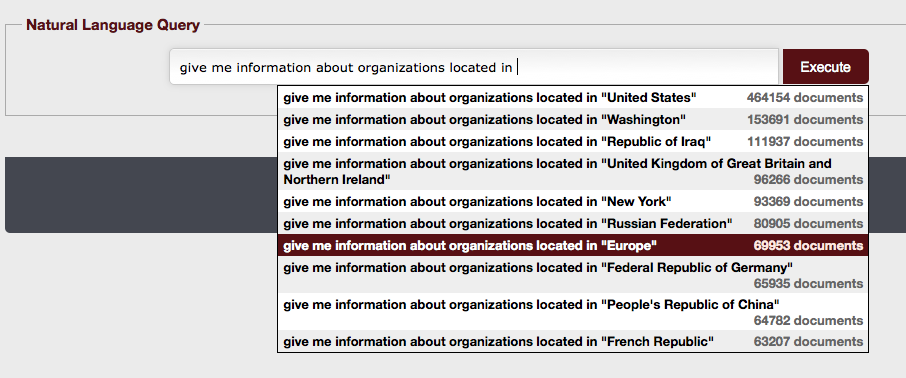
- The MOLTO KRI, Knowledge Reasoning Infrastructure, demonstrates the possibility of adding a natural language query language to retrieve answers from an OWL database. In this way, a query like Give me information about all organizations located in Europe is interpreted as the machine understandable SPARQL statement:
SELECT DISTINCT ?organization ?organization_label WHERE {
?organization
. ?organization
?organizationloc. ?organizationloc "Europe". ?organization ?organization_label . }
On the more technical level, MOLTO released:
- first version of the Python plugin for GF (based on the planned C plugin). The plugin makes GF primitives available from the Natural Language Toolkit (http://www.nltk.org/), an open source collection of Python modules for research and development in natural language processing and text analytics, with distributions for Windows, Mac OSX and Linux.
- (version 3.2 of GF, which features updates of the pgf format, complete type checker for dependent types, exhaustive generation of ASTs via lambda prolog, support for probabilities in the abstract syntax, random generation and parse results guided by probability, and example based grammar generation.) DISCUSS WITH AR
- (Urdu resource grammar library and Turkish morphology) DISCUSS WITH AR
Expected final results and their potential impact and use
The expected final product of MOLTO is a software toolkit made available via the MOLTO website. It will consist in a family of open-source software products:
- a grammar development tool, available as an IDE and an API, to enable the use as a plug-in to web browsers, translation tools, etc, for easy construction and improvement of translation systems and the integration of ontologies with grammars
- a translator’s tool, available as an API and some interfaces in web browsers and translation tools
- a grammar library for linguistic resources
- a grammar library for the domains of mathematics, patents, and cultural heritage
These tools will be portable to different platforms as well as generally portable to new domains and languages. By the end of the project, MOLTO expects to have grammar resource libraries for 18 languages, whereas MOLTO use cases will target between 3 and 15 languages.
The main societal impact of MOLTO will be on contributing to a new perception for the possibilities of machine translation, moving away from the idea that domain-specific high-quality translation is expensive and cumbersome. MOLTO tools will change this view by radically lowering the effort needed to provide high-quality scoped translation for applications where the content has enough semantic structure.
Public website
The MOLTO website at http://www.molto-project.eu publishes the results, the news and all information related to the project. In addition, a Twitter feed is also available at http://twitter.com/moltoproject.
- Printer-friendly version
- Login to post comments
- Slides
What links here
No backlinks found.

