1. Project Objective
The EU project MOLTO - Multilingual Online Translation, started on March 1, 2010 and will run until June 2013.The Consortium, comprising the universities of Gothenburg, Helsinki and Polytechnical Barcelona together with the industrial Bulgarian partner OntoText, has been enlarged by the addition of University of Zurich and of the Dutch Be Informed.
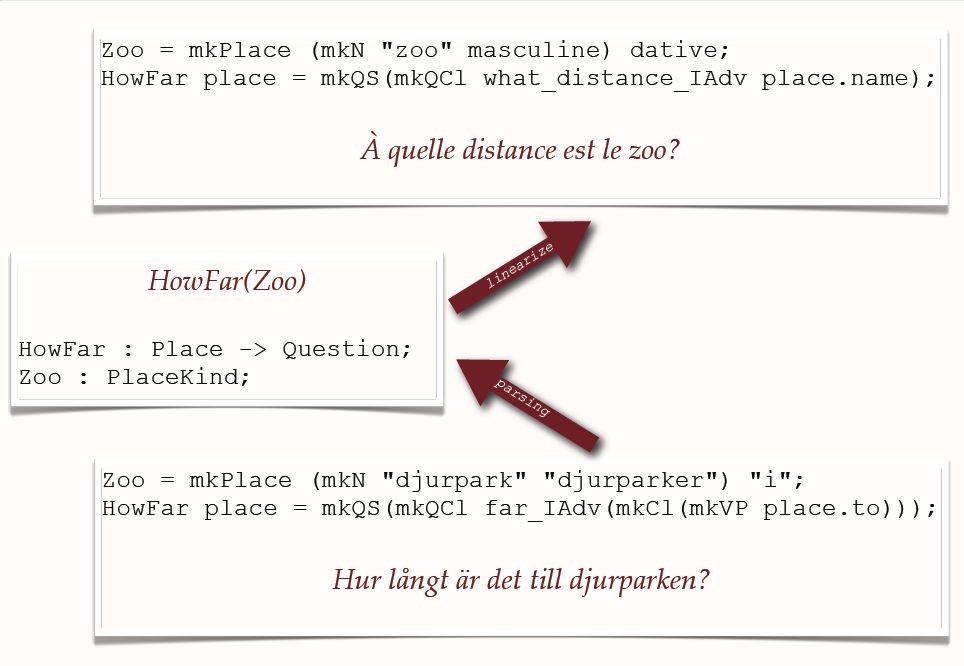 MOLTO's multilingual translation tools use multilingual grammars based on semantic interlinguas and statistical machine translation to simplify the production of multilingual documents without sacrificing the quality. The interlinguas are designed to model domain semantics and are equipped with reversible generation functions: namely translation is obtained as a composition of parsing the source language and generating the target language.
MOLTO's multilingual translation tools use multilingual grammars based on semantic interlinguas and statistical machine translation to simplify the production of multilingual documents without sacrificing the quality. The interlinguas are designed to model domain semantics and are equipped with reversible generation functions: namely translation is obtained as a composition of parsing the source language and generating the target language.
An implementation of this technology is alread available in the Grammatical Framework, GF. As a result of the MOLTO project work, GF technologies are complemented by the use of ontologies, viewed as formalisms employed by the semantic web for capturing structural relations, and by methods of statistical machine translation (SMT) for improving robustness and extracting grammars from linguistic data.
MOLTO is committed to dealing with 15 languages, which includes 12 official languages of the European
Union - Bulgarian, Danish, Dutch, English, Finnish, French, German, Italian, Polish, Romanian, Spanish, and Swedish - and 3 other languages - Catalan, Norwegian, and Russian. In addition, there is constant on-going work on creating new resource grammars, in particular Arabic, Farsi, Hebrew, Hindi/Urdu, Icelandic, Japanese, Latvian, Maltese, Portuguese, and Swahili. The coverage and accuracy of the GF grammar library resource varies among the different languages and is documented on the web site of GF.
When comparing MOLTO to popular translation tools like Systran (Babelfish) and Google Translate, the main difference is the intended user of the tools: these tools target end-users of information whereas MOLTO targets producers of information.
By producers of information, MOLTO is able to handle well scenarios in which the language is constrained, as examples one may consider e-commerce sites, where products are often described with repeated linguistic expressions (e.g. Wikipedia articles, contracts, business letters, user manuals, and software localization), but even social networks often display usage of common phrases ("Happy birthday!" "I like it" "The hotel is located ...." "Your reservation is confirmed"). Ideally, MOLTO tools will enable publishers of websites to add multilinguality with little effort but most importantly with the certification that the meaning of the message conveyed stays unaltered across languages. MOLTO is also working on a multilingual semantic wiki .............
There is a well-known trade-off in machine translation: one cannot at the same time reach full coverage and full precision. In this trade-off, Systran and Google have opted for coverage whereas MOLTO opts for precision in domains with a well-understood codified language, either because it is of technical nature or because of common everyday usage.
The domains considered during the MOLTO project show a range of features of constrained natural languages: mathematical exercises and biomedical patents employ a technical and sophisticated jargon, whereas museum object descriptions use a language accessible to anybody.
- Printer-friendly version
- Login to post comments
- Slides
What links here
No backlinks found.

