2. Results
The expected final product of MOLTO is an open-source software suite of tools comprising a grammar development environment, an application programming interface and environment to assist the translators' workflow, and sample application grammar libraries for the domains of mathematical word problems, biomedical patents, and cultural artefacts.
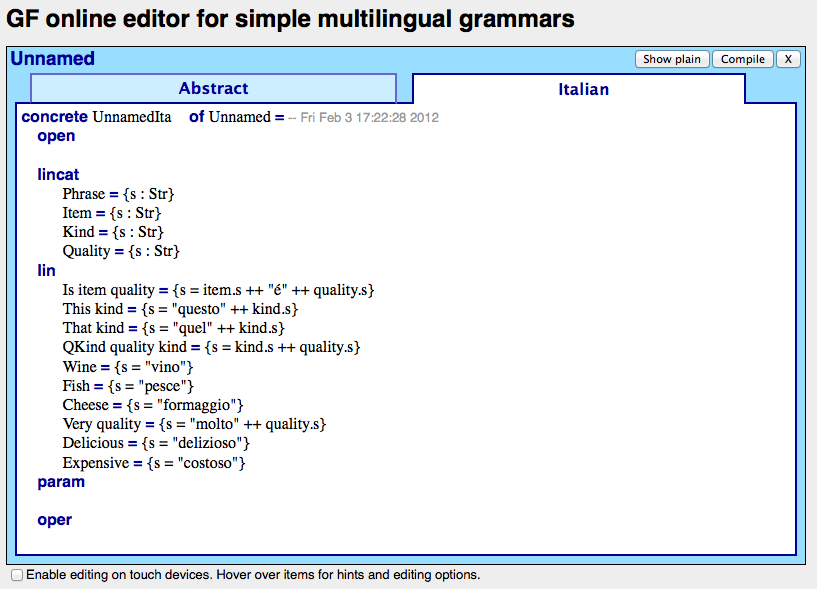 Translation systems in MOLTO rely on multilingual grammars written in the GF programming language. Until now, the development environments available to GF grammarians consisted of a generic text editor, such as Emacs, used in combination with the GF interactive command shell, and the online GF documentation. This is a simple and effective environment for the experienced grammar developer. To better support less experienced grammar developers, one of the goals of the MOLTO project is to create an Integrated Development Environment for grammar development. The GF Simple Editor (by Thomas Hallgren), an initial prototype of a web-based grammar development environment that offers the same core functionality as the traditional environment is now available at http://www.grammaticalframework.org/demos/gfse. Its main features include grammar editing, grammar compilation, error detection, testing and visualization. Moreover, it enables the creation of web-based translation systems without installation of any software, as it is using web services to carry out compilation and interpretation tasks, and thus gives quick access to GF to novice and occasional users. Intended scenario for this editor is in supporting fast testing and prototyping of example grammars in tutorial settings, for instance during teaching and demonstrating GF.
Translation systems in MOLTO rely on multilingual grammars written in the GF programming language. Until now, the development environments available to GF grammarians consisted of a generic text editor, such as Emacs, used in combination with the GF interactive command shell, and the online GF documentation. This is a simple and effective environment for the experienced grammar developer. To better support less experienced grammar developers, one of the goals of the MOLTO project is to create an Integrated Development Environment for grammar development. The GF Simple Editor (by Thomas Hallgren), an initial prototype of a web-based grammar development environment that offers the same core functionality as the traditional environment is now available at http://www.grammaticalframework.org/demos/gfse. Its main features include grammar editing, grammar compilation, error detection, testing and visualization. Moreover, it enables the creation of web-based translation systems without installation of any software, as it is using web services to carry out compilation and interpretation tasks, and thus gives quick access to GF to novice and occasional users. Intended scenario for this editor is in supporting fast testing and prototyping of example grammars in tutorial settings, for instance during teaching and demonstrating GF.
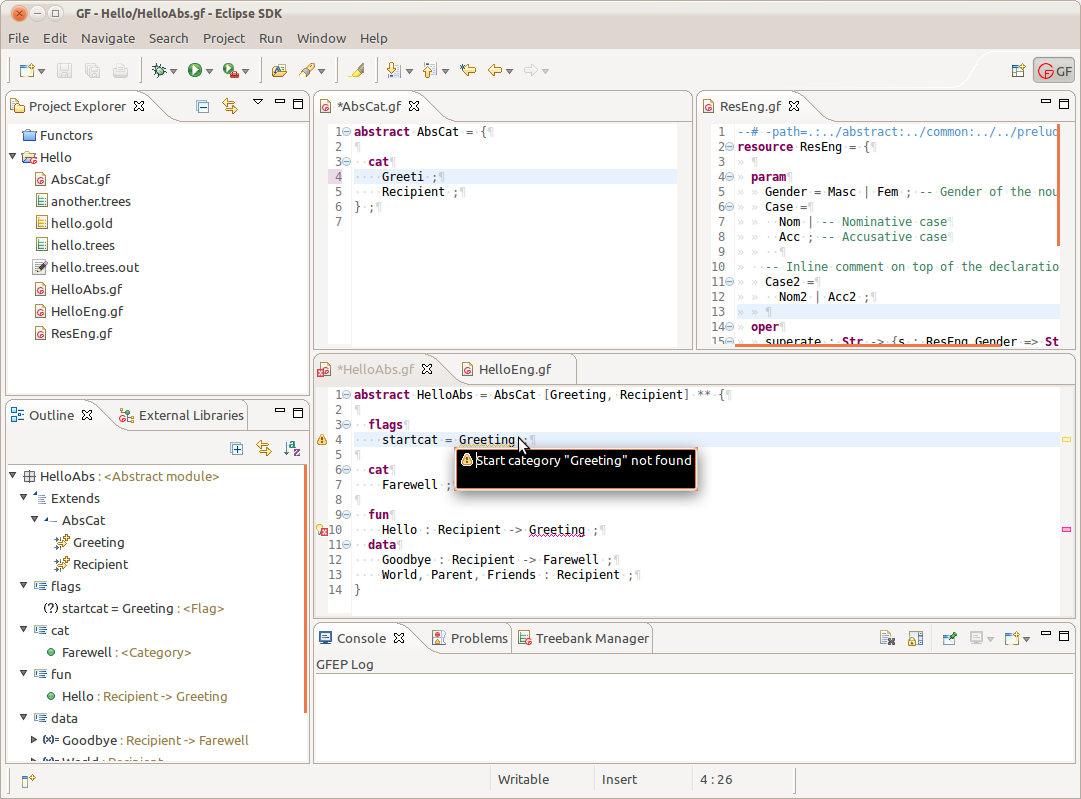 A different, more sophisticated high-level integrated development environment is based on the Eclipse platform and specifically tailors GF grammar-writing. The GF Eclipse plugin (by John Camilleri) currently features real-time syntax checking, automatic code formatting, import-aware auto-complete suggestions, cross-reference resolution, inline contextual documentation, "New Module" wizards, external library browsing, launch shortcuts to the GF shell, and a visual tool for running treebank test suites. These new, powerful, time-saving development tools are aimed at both new users and GF veterans alike. It is available online at http://www.grammaticalframework.org/eclipse/ and at http://www.molto-project.eu/wiki/gf-eclipse-plugin.
A different, more sophisticated high-level integrated development environment is based on the Eclipse platform and specifically tailors GF grammar-writing. The GF Eclipse plugin (by John Camilleri) currently features real-time syntax checking, automatic code formatting, import-aware auto-complete suggestions, cross-reference resolution, inline contextual documentation, "New Module" wizards, external library browsing, launch shortcuts to the GF shell, and a visual tool for running treebank test suites. These new, powerful, time-saving development tools are aimed at both new users and GF veterans alike. It is available online at http://www.grammaticalframework.org/eclipse/ and at http://www.molto-project.eu/wiki/gf-eclipse-plugin.
Controlled natural languages are controlled subsets of natural languages, which are normally used in technical domains. The purpose of these languages is to reduce the complexity involved in natural languages, and to eliminate the ambiguity. The users of these languages are experts within their domain, and are trained to use these languages.
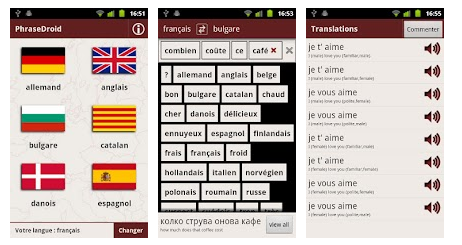 The MOLTO Phrasebook (by Aarne Ranta et al.) is one such controlled natural language, whose domain is that of touristic phrases. It covers greetings and travel phrases such as "this fish is delicious", "how far is the airport from the hotel" in 17 languages. The translations show the kind of quality that can be hoped for when using a GF grammar that can handle disambiguation in conveying gender and politeness, for instance from English to Italian. It is available both on the web from http://www.grammaticalframework.org/demos/phrasebook/ and as a stand-alone, offiline Android application, the PhraseDroid, from http://tinyurl.com/7tyzvfd. Screenshots of the mobile application are shown in the image on the side.
The MOLTO Phrasebook (by Aarne Ranta et al.) is one such controlled natural language, whose domain is that of touristic phrases. It covers greetings and travel phrases such as "this fish is delicious", "how far is the airport from the hotel" in 17 languages. The translations show the kind of quality that can be hoped for when using a GF grammar that can handle disambiguation in conveying gender and politeness, for instance from English to Italian. It is available both on the web from http://www.grammaticalframework.org/demos/phrasebook/ and as a stand-alone, offiline Android application, the PhraseDroid, from http://tinyurl.com/7tyzvfd. Screenshots of the mobile application are shown in the image on the side.
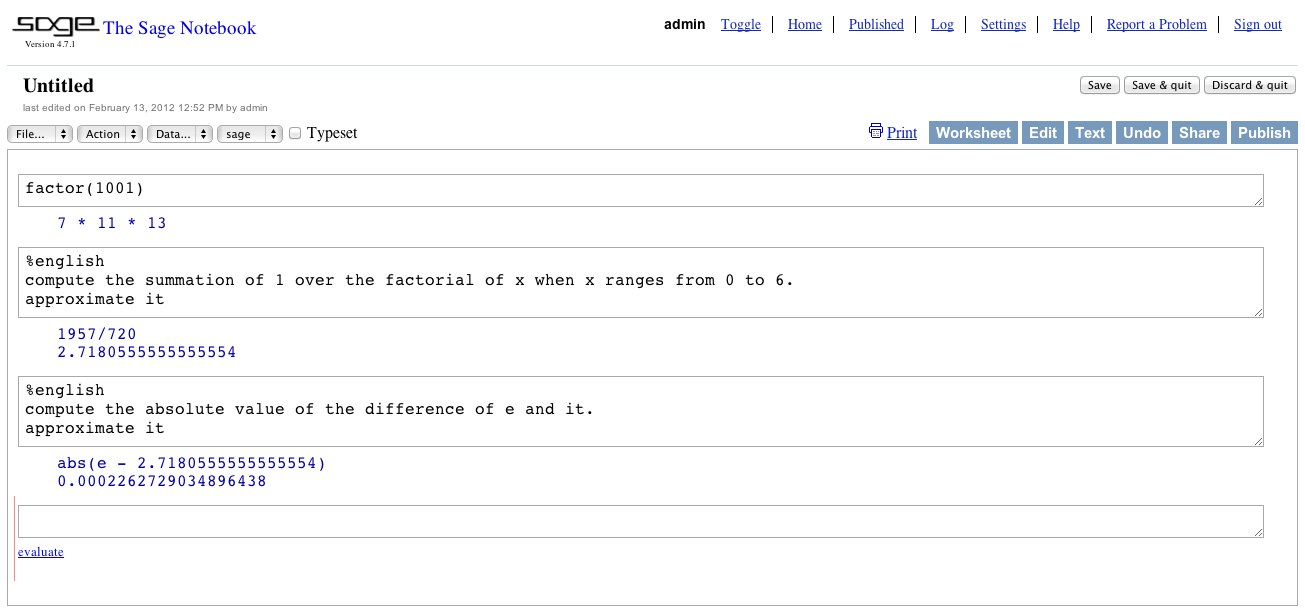 A different kind of controlled natural language is one that is used to command an interactive software system, for instance a computational engine such as Sage. The GFSage software application (by Jordi Saludes) shows a command-line tool able to take commands in natural language, have them executed by Sage, and have the answers rendered in natural language too. The image on the side shows the web interface of Sage augmented by the MOLTO natural language command module. Note that this application demonstrates how a MOLTO library can add multimodality to a system originally developed with keyboard input/output as user interface. In fact, by piping the results to a speech engine, one can have the results aurally thus increasing accessibility of the computational systems to the visually impaired. The natural language interface relies on the Mathematical Grammar Library that can be tested at http://www.grammaticalframework.org/demos/minibar/mathbar.html and documentation on the GFSage module is available as deliverable http://tinyurl.com/78bh4ap from the MOLTO wiki http://www.molto-project.eu/wiki/d62-prototype-comanding-cas.
A different kind of controlled natural language is one that is used to command an interactive software system, for instance a computational engine such as Sage. The GFSage software application (by Jordi Saludes) shows a command-line tool able to take commands in natural language, have them executed by Sage, and have the answers rendered in natural language too. The image on the side shows the web interface of Sage augmented by the MOLTO natural language command module. Note that this application demonstrates how a MOLTO library can add multimodality to a system originally developed with keyboard input/output as user interface. In fact, by piping the results to a speech engine, one can have the results aurally thus increasing accessibility of the computational systems to the visually impaired. The natural language interface relies on the Mathematical Grammar Library that can be tested at http://www.grammaticalframework.org/demos/minibar/mathbar.html and documentation on the GFSage module is available as deliverable http://tinyurl.com/78bh4ap from the MOLTO wiki http://www.molto-project.eu/wiki/d62-prototype-comanding-cas.
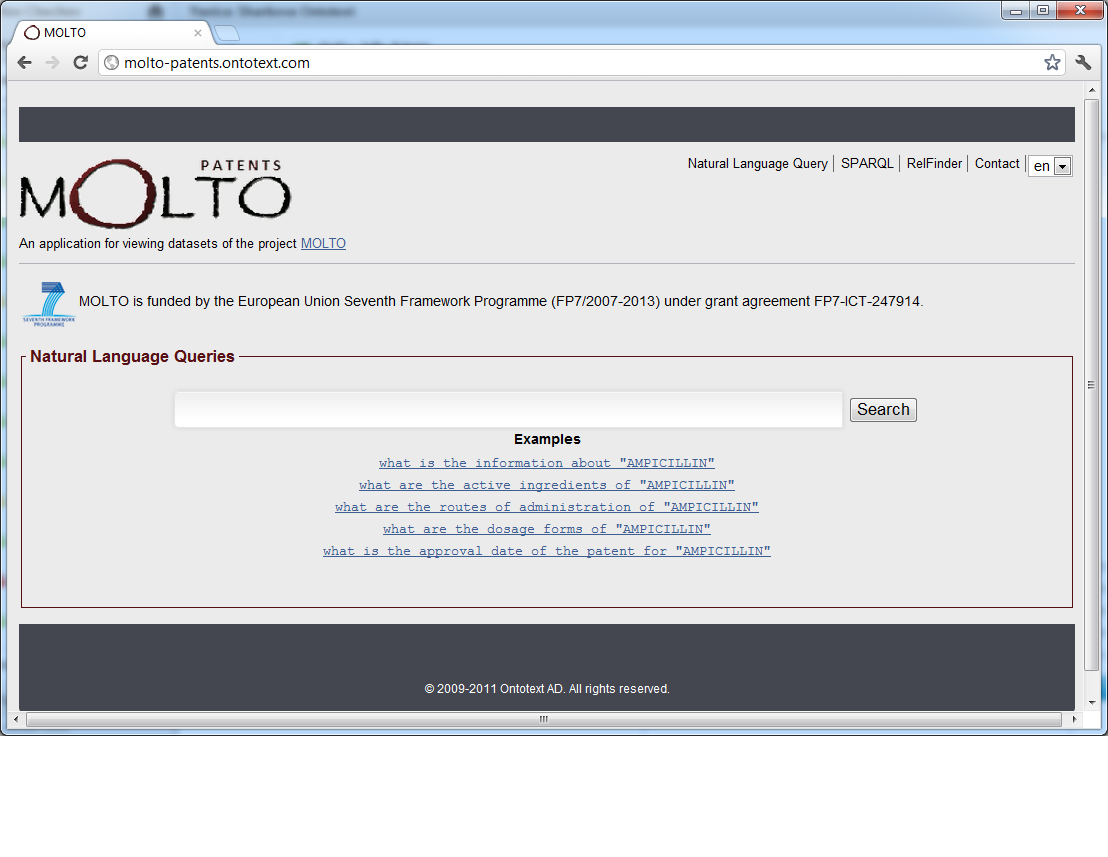 To demonstrate the MOLTO Knowledge Reasoning Infrastructure, the Patent retrieval prototype (by Milen Chechev from Ontotext in collaboration with the UPC and the UGOT teams), at http://molto-patents.ontotext.com, shows examples of queries in natural language to a set of patents in the pharmaceutical domain. Users can ask question in French and English like 'what are the active ingredients of "AMPICILLIN"', 'que sont les formes posologiques de "AMPICILLIN"'. The system is still under development: at present the online interface allows to browse the retrieved patents and returns the semantic annotations that explain why any particular patent has matched the user's criteria. Similar technology for knowledge retrieval is being applied also in the case of cultural heritage, namely with descriptions of artefacts from the museum of Gothenburg, in order to allow multilingual query and retrieval. For this task, an ad-hoc ontology has been created and its preliminary GF application grammar can be tested by selecting "Painting.pgf" at http://www.grammaticalframework.org/demos/minibar/minibar.html.
To demonstrate the MOLTO Knowledge Reasoning Infrastructure, the Patent retrieval prototype (by Milen Chechev from Ontotext in collaboration with the UPC and the UGOT teams), at http://molto-patents.ontotext.com, shows examples of queries in natural language to a set of patents in the pharmaceutical domain. Users can ask question in French and English like 'what are the active ingredients of "AMPICILLIN"', 'que sont les formes posologiques de "AMPICILLIN"'. The system is still under development: at present the online interface allows to browse the retrieved patents and returns the semantic annotations that explain why any particular patent has matched the user's criteria. Similar technology for knowledge retrieval is being applied also in the case of cultural heritage, namely with descriptions of artefacts from the museum of Gothenburg, in order to allow multilingual query and retrieval. For this task, an ad-hoc ontology has been created and its preliminary GF application grammar can be tested by selecting "Painting.pgf" at http://www.grammaticalframework.org/demos/minibar/minibar.html.
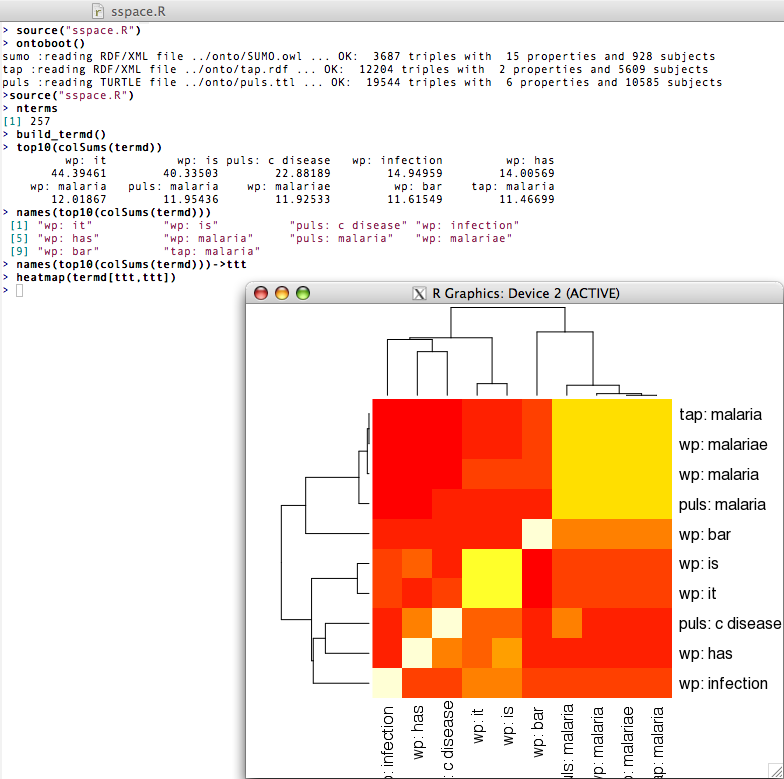 The MOLTO translation environment is being developed (by UHEL with contributions of UGOT) as a customization the GlobalSight translation system (www.globalsight.com). The aim is to be able to embed MOLTO translation tools to a third-party translation platform. MOLTO tools are designed with a focus only on translation. GlobalSight is an open source translation management platform, which provides the infrastructure needed in a professional translation workflow. More specifically, a MOLTO translation editor will be available on the side of conventional editors and be characterized by the possibility of fetching terms from the FactForge ontology via the TermFactory database, allowing to import and export terms in TermFactory. Terminology work is also supported by OntoR, an ontology extraction system (by Seppo Nyrkkö) implemented as s semi-supervised machine learning process, where new term dictionary candidates may be found in given text, by finding "closest matches" in previously known _ontologies_ (i.e. hierarchical vocabulary, term structure, usually industry or domain specific). A corpus-harvested new term can be _aligned_ with its closest matches in an prior existing term ontology. New term's functional and semantic environment is analyzed, and the feature variables extracted are compared to values of previously known terms. The user is given the supervision control to decide the best alignment match and thus refine the ontology incrementally. These tools are not yet ready for distribution but a preview can be seen during the project meetings' open days.
The MOLTO translation environment is being developed (by UHEL with contributions of UGOT) as a customization the GlobalSight translation system (www.globalsight.com). The aim is to be able to embed MOLTO translation tools to a third-party translation platform. MOLTO tools are designed with a focus only on translation. GlobalSight is an open source translation management platform, which provides the infrastructure needed in a professional translation workflow. More specifically, a MOLTO translation editor will be available on the side of conventional editors and be characterized by the possibility of fetching terms from the FactForge ontology via the TermFactory database, allowing to import and export terms in TermFactory. Terminology work is also supported by OntoR, an ontology extraction system (by Seppo Nyrkkö) implemented as s semi-supervised machine learning process, where new term dictionary candidates may be found in given text, by finding "closest matches" in previously known _ontologies_ (i.e. hierarchical vocabulary, term structure, usually industry or domain specific). A corpus-harvested new term can be _aligned_ with its closest matches in an prior existing term ontology. New term's functional and semantic environment is analyzed, and the feature variables extracted are compared to values of previously known terms. The user is given the supervision control to decide the best alignment match and thus refine the ontology incrementally. These tools are not yet ready for distribution but a preview can be seen during the project meetings' open days.
- Printer-friendly version
- Login to post comments
- Slides
What links here
No backlinks found.

